

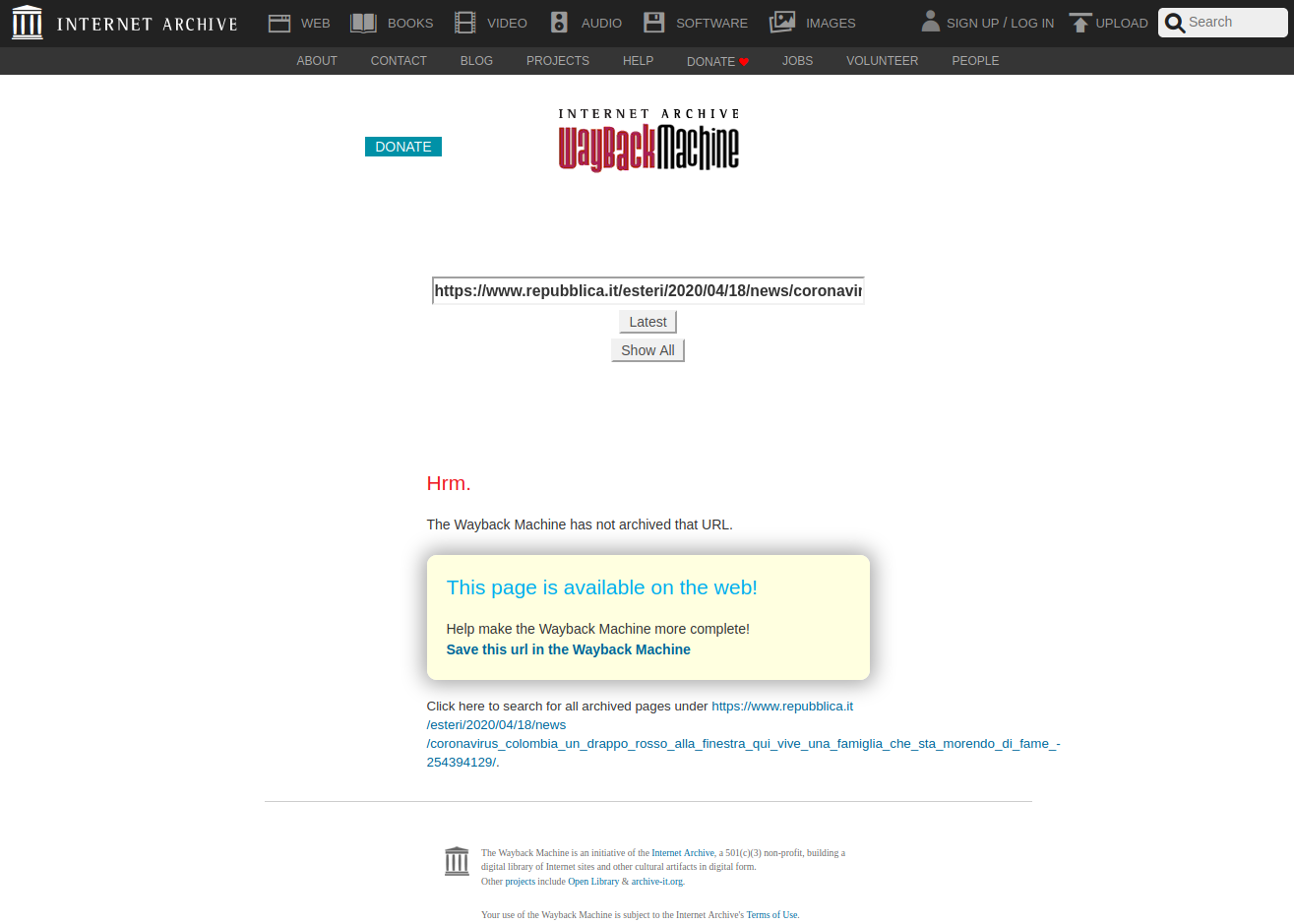
Mentre raccoglievo dati e prove per questo mio articolo sul plagio effettuato da Repubblica ai danni di El País ho notato un fenomeno che mi ha spiazzato: le copie dei siti archiviate da Archive.org non sono permanenti.
Questo è un problema molto serio per chiunque faccia affidamento su Archive.org per la conservazione di copie che documentino lo stato o il contenuto di un sito a una certa data.
Quando ho iniziato l’indagine sul caso di plagio suddetto, la prima cosa che ho fatto, come sempre, è stata creare uno screenshot dell’articolo di Repubblica nello stato in cui era (cioè privo di qualunque riferimento alla fonte) e poi salvarne una copia su Archive.org.
{kind=link}
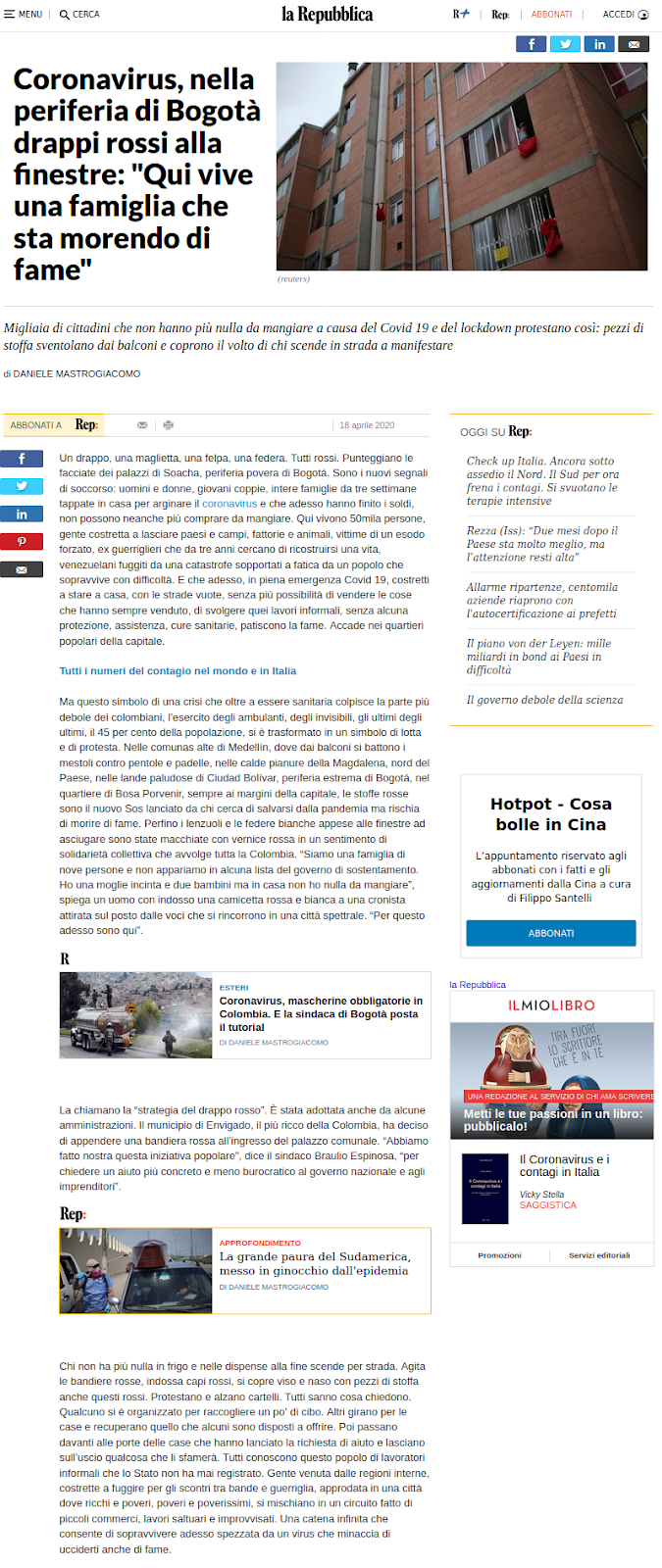
L’articolo era stato pubblicato a questo URL (che qui ho alterato per non dare ranking):
L’avevo salvato su Archive.org due volte (una qui il 21/4/2020 e qui il 20/4/2020), ma entrambe le copie sono sparite stamattina. Poco dopo la pubblicazione iniziale di questo articolo, Archive.org ha iniziato a redirigere questi link verso una nuova copia (web.archive.org/web/20200423130619...) che contiene già il testo modificato (screenshot qui sotto).
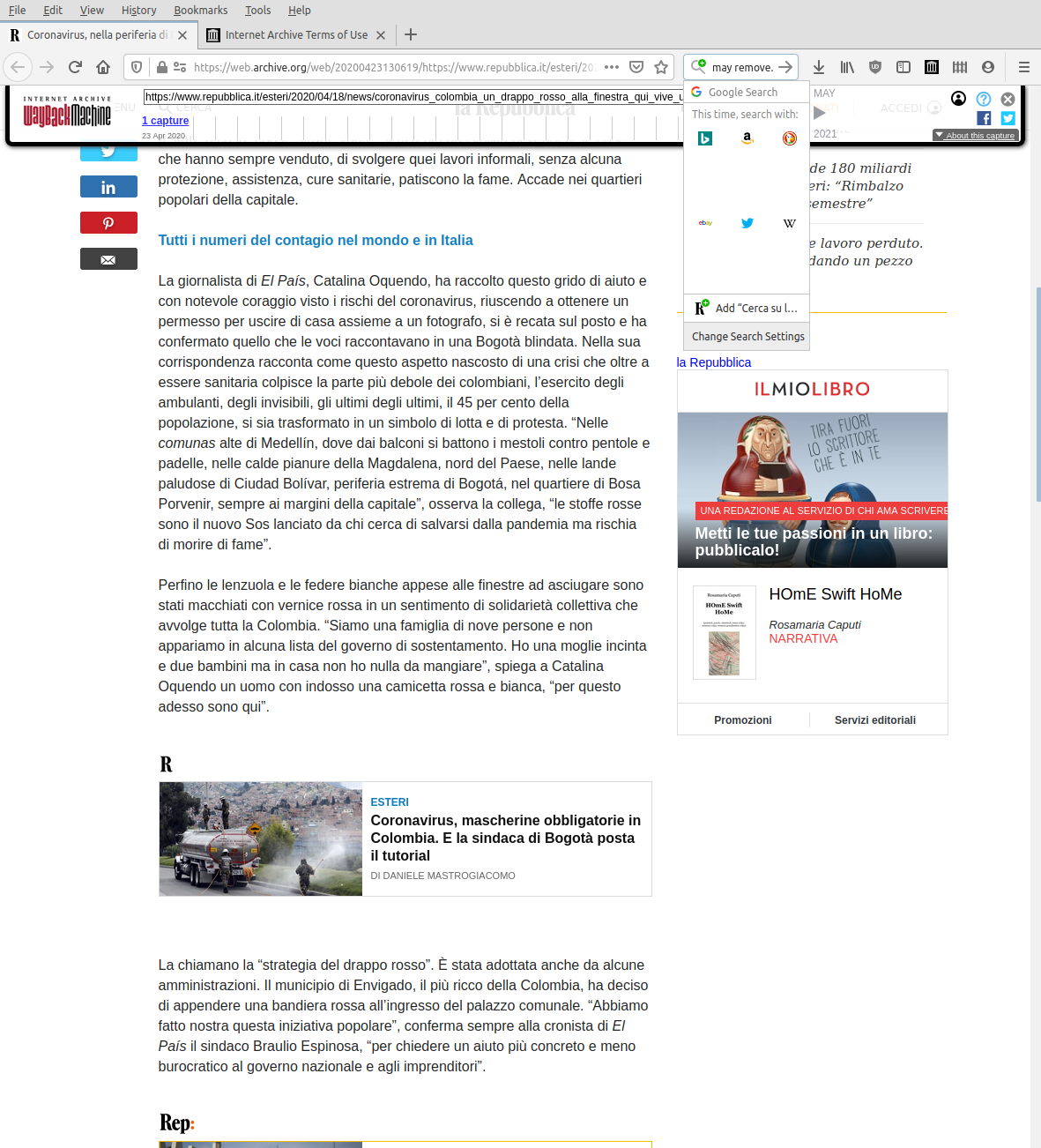
Già questo è preoccupante, ma c’è di più. Ieri le copie su Archive.org c’erano ancora, ma erano alterate. Pur avendo la data del 20 e 21/4, mostravano già la versione aggiornata dell’articolo di Repubblica, cancellando ogni traccia del plagio e anzi creando un’apparente traccia storica che lo nega.
È possibile che Repubblica abbia richiesto un takedown DMCA delle copie precedenti, come hanno fatto le persone citate qui o qui e come previsto dai Terms of Use (“If the author or publisher of some part of the Archive does not want his or her work in our Collections, then we may remove that portion of the Collections without notice.”).
Se Archive.org cancella i propri contenuti o se è possibile configurare una pagina Web in modo che Archive.org ne mostri una versione alterata, allora Archive.org non può essere usato come sito di archiviazione per questo genere di ricerca.
Sto cercando di capire come sia possibile. Se avete qualche idea, contattatemi o scrivete nei commenti.
2020/04/23 18:40
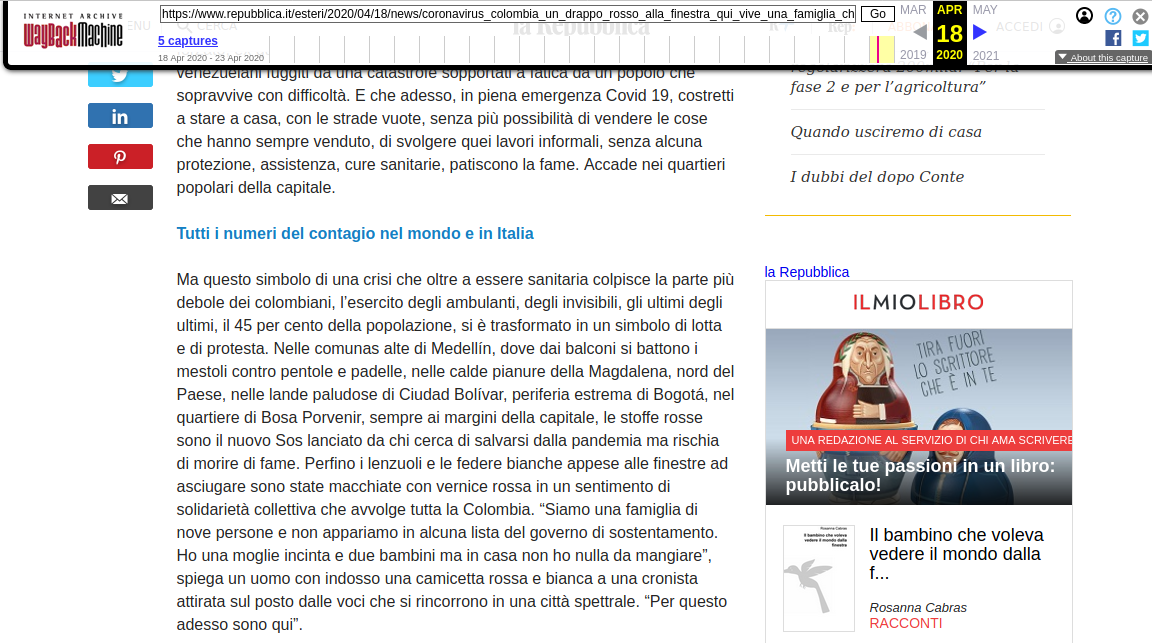
Mi ha scritto Mark Graham, direttore della Wayback Machine presso l’Internet Archive (Archive.org): si tratta di un effetto nel ritardo nell’indicizzazione sui server, che stanno aggiungendo oltre un miliardo di URL al giorno e fanno fatica a stare al passo, ma recupereranno entro qualche giorno. Non sono stati persi dati.
Se fosse stato escluso qualcosa, mi ha precisato, per esempio a causa di una richiesta di takedown DMCA, sullo schermo comparirebbe l’indicazione “Excluded”.
In effetti in questo momento vedo 5 catture, e quella del 18/4 contiene la versione non modificata dell’articolo di Repubblica:
Quindi il caso specifico di Repubblica è chiarito, ma resta la questione della effettiva possibilità di rimozione a seguito di richiesta di takedown. Per chi usa Archive.org per documentare una situazione o avere una copia permanente di contenuti che potrebbero scomparire, questo è un fattore da considerare con attenzione.
Questo articolo vi arriva gratuitamente e senza pubblicità grazie alle donazioni dei lettori. Se vi è piaciuto, potete incoraggiarmi a scrivere ancora facendo una donazione anche voi, tramite Paypal (paypal.me/disinformatico), Bitcoin (3AN7DscEZN1x6CLR57e1fSA1LC3yQ387Pv) o altri metodi.