Questo articolo è disponibile anche in versione podcast audio.
Ho già raccontato in una puntata molto recente di questo podcast, quella del 26 agosto scorso, gli incredibili e rapidissimi progressi dei programmi di intelligenza artificiale dedicati alla generazione di immagini, come Midjourney, DALL-E o Stable Diffusion, ma torno sull’argomento perché in queste ultime settimane quei progressi sono stati davvero straordinari, con novità su moltissimi fronti.
Se siete artisti digitali, o se il vostro lavoro è legato in qualche modo alle immagini, comprese quelle fotografiche e in movimento, è decisamente il momento di informarsi e riflettere seriamente su dove ci stia portando la tecnologia.
La prima novità è che è già crollata una delle più importanti barriere di accesso che citavo nel podcast solo tre settimane fa, ossia la difficoltà di installazione, che richiedeva computer potenti e spingeva molti utenti a rivolgersi a servizi online a pagamento o a rinunciare del tutto a sperimentare questi software. È uscito infatti Diffusion Bee, reperibile gratuitamente presso Diffusionbee.com, che è una versione di Stable Diffusion che si scarica e si installa con pochi clic su qualunque Mac dotato di processore M1 o M2.
Questo significa che moltissime persone possono cominciare a provare questi generatori, che creano immagini estremamente realistiche e artistiche partendo da un prompt, ossia da una semplice descrizione testuale in inglese del soggetto che si desidera, e lo possono fare gratuitamente e privatamente.
[Il disegno di Scarlett Johansson in versione sirena mostrato qui sopra è un’immagine generata con il prompt
“A beautiful portrait of scarlett johansson as a mermaid in a river of
the amazon, ayahuasca, fantasy art, highly detailed, matte painting,
visionary art”
e pubblicata su Lexica.art.]
Diffusion Bee richiede molta memoria libera (16 GB sono consigliati), rallenta parecchio il computer e richiede tempo per generare una buona immagine sintetica, ma funziona e offre totale libertà creativa.
Inevitabilmente, questa libertà comporta delle conseguenze controverse. La più ovvia è che un’installazione sul proprio computer può essere facilmente modificata per togliere le restrizioni che nei generatori accessibili online impediscono di generare contenuti estremamente violenti o immagini fotorealistiche di celebrità o di minori in qualunque posa o situazione, soprattutto di natura intima. L’installazione locale inoltre permette di rimuovere i watermark o indicatori invisibili che rivelano che si tratta di immagini artificiali.
Se temevate che i deepfake fossero un problema, non avete ancora visto cosa può fare un generatore di immagini quando gli vengono tolti i freni inibitori. Per esempio, c’è chi si indigna perché la Sirenetta nel prossimo film omonimo della Disney è di colore e quindi propone di usare questi software per creare una versione alternativa tutta bianca del film, indistinguibile da quella autentica.

Un’altra conseguenza controversa è che diventa possibile praticamente per chiunque creare dei falsi fotografici difficilmente distinguibili dalla realtà. In sostanza, non potremo più fidarci di un’immagine se non abbiamo una garanzia robusta della sua provenienza e autenticità.
Per esempio, in occasione dell’anniversario degli attentati alle Torri Gemelle e al Pentagono dell’11 settembre 2001 sono state diffuse su Twitter delle fotografie false, create da uno di questi generatori basati sull’intelligenza artificiale, che mostrano pompieri sorridenti che si fanno dei selfie davanti agli edifici in fiamme.
Lenny’s tweet is perhaps a joke, but the images are interesting. They are AI generated probably with Stable Diffusion.
— HoaxEye (@hoaxeye) September 14, 2022
There are several artifacts that are present in AI pics. I’m worried about the day when those signs are no longer visible. H/t @Valdevia_Art & @PicPedant pic.twitter.com/rrqwj4k5md
Per un osservatore non esperto, queste fotografie sintetiche di dubbio gusto sono indistinguibili da quelle reali. Per un complottista sono la conferma inoppugnabile delle sue teorie.
---
Senza arrivare a questi livelli di sovvertimento della realtà, le comunità degli artisti digitali sono agitatissime. In Colorado, un’immagine generata da Midjourney ha vinto il primo premio in un concorso d’arte, nella categoria degli artisti digitali emergenti. Molti artisti in carne e ossa si sono infuriati, ma Jason Allen, il creatore delle istruzioni testuali che hanno prodotto l’immagine vincente, ha risposto semplicemente che “È finita. L’intelligenza artificiale ha vinto. Gli umani hanno perso. L’arte è morta” (BBC).

Il fiume di immagini sintetiche generate da questi programmi ha spinto numerose comunità online di arte digitale a bandirle completamente; DeviantArt e ArtStation per ora resistono, ma sono invase da immagini generate.
Il problema, obiettano queste comunità, è che le
intelligenze artificiali campionano il lavoro di altri artisti (umani) per
creare le proprie immagini, e ne possono anche imitare lo stile. In alcuni
casi ne imitano persino le firme.
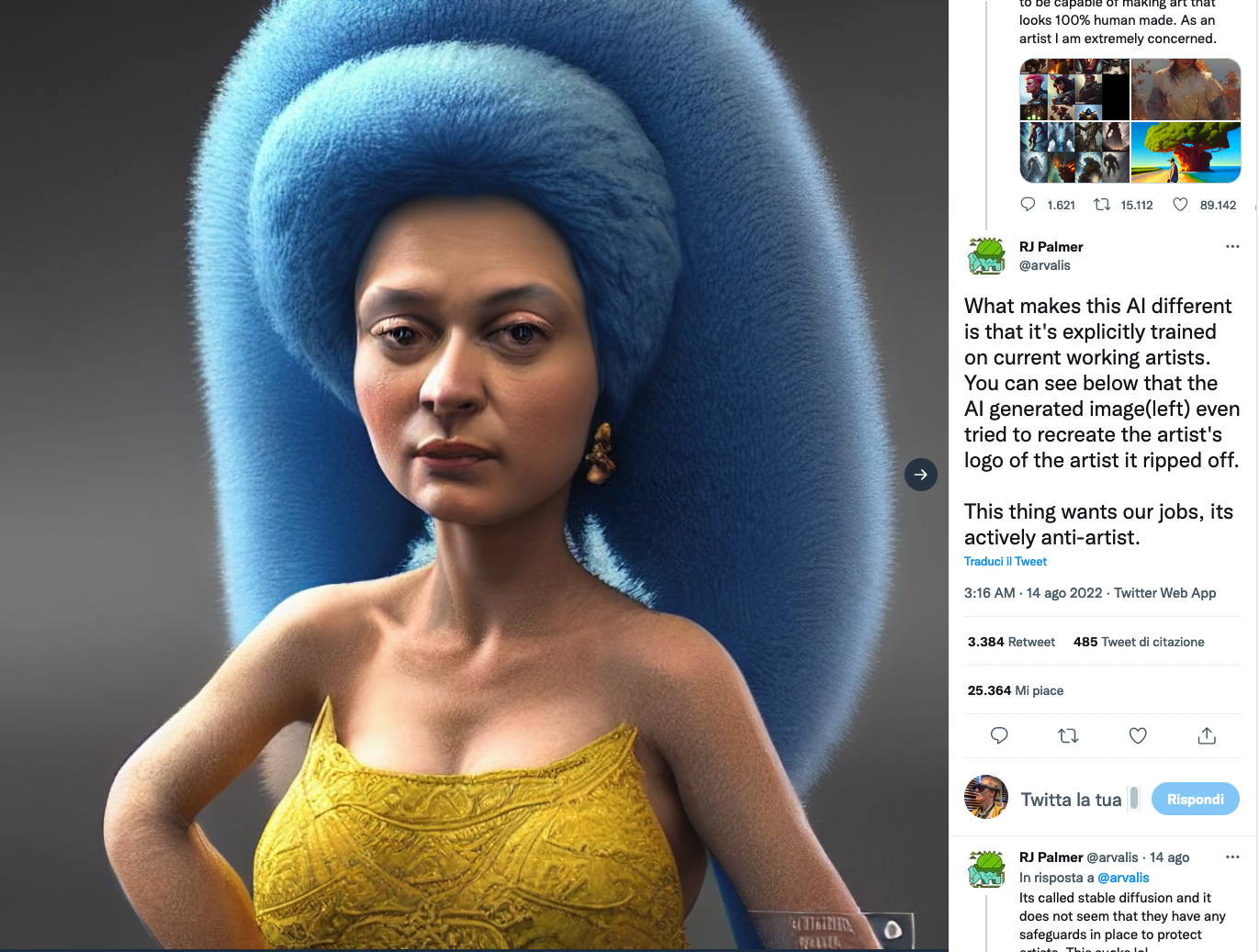
Ma ci sono anche aspetti positivi in questa esplosione di immagini
automatiche: diventa possibile una sorta di democratizzazione dell’arte, dove
non è necessario saper disegnare o dipingere per fare arte o addirittura creare un
intero album a fumetti in tre giorni, ma è sufficiente saper comporre i
prompt, ossia le istruzioni che guidano la generazione delle immagini.
L’intelligenza artificiale sarebbe quindi una sorta di assistente, un po’ come
i normali programmi di grafica rendono facile produrre zone uniformemente
colorate o sfumate.
Va detto che comporre questi prompt non è proprio facile e richiede una certa competenza e cultura, come hanno scoperto i primi aspiranti fumettisti che si sono lanciati nell’impresa. Per dare buoni risultati, i prompt devono essere frasi complesse e articolate, nelle quali la scelta di un singolo aggettivo può cambiare completamente il risultato che si ottiene.
[I prompt sono cose come questa: “Beautiful crying! female mechanical android!, half portrait, intricate detailed environment, photorealistic!, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha”]
Se volete farvene un’idea, visitate Lexica.art, che è un grandissimo archivio di immagini sintetiche accompagnate dai prompt corrispondenti.
Se si riesce a padroneggiare queste istruzioni si ottengono risultati
notevolissimi.
Ma non è finita. Le applicazioni della generazione di immagini continuano ad aumentare. Per esempio, è stato proposto di usare questi generatori per assistere gli stilisti nella creazione di capi di abbigliamento. Una demo realizzata con il software DALL-E mostra un video di una modella che nella realtà indossa solo pantaloncini e una canotta di colore uniforme mentre si mette in posa, ma nell’elaborazione digitale indossa vestiti che cambiano in continuazione, seguendo i suoi movimenti e i cambiamenti dell’inquadratura.
AI fashion show using dall-e to generate hundreds of outfits of the day after tomorrow. An interesting way to brainstorm costume and fashion design ideas.
— Paul Trillo (@paultrillo) August 23, 2022
Collab with @shyamagolden @OpenAI #dalle2 #dalle #aiart pic.twitter.com/Fewhk529r7
Oltre a essere un ausilio per la creatività degli stilisti, generando centinaia di varianti in pochi minuti, questo software permetterebbe di ridurre i tempi di lavoro delle modelle per i video promozionali, visto che non avrebbero più bisogno di svestirsi e rivestirsi e sfilare per ogni capo: sfilerebbero una volta sola e poi ci penserebbe l’intelligenza artificiale a fare tutto il resto.
E c’è un passo ancora più sofisticato. È uscito da poco Runway, un software che promette di creare intere scene animate o video fotorealistici partendo da semplici descrizioni testuali. Voi scriverete il copione e l’intelligenza artificiale genererà tutto il film, con gli attori e le musiche che volete voi.
Make any idea real. Just write it.
— Runway (@runwayml) September 9, 2022
Text to video, coming soon to Runway.
Sign up for early access: https://t.co/ekldoIshdw pic.twitter.com/DCwXcmRcuK
In un modo o nell’altro, insomma, nei prossimi anni verranno sovvertiti e rivoluzionati moltissimi settori della produzione artistica, e bisognerà inventarsi nuovi modelli commerciali e di copyright e nuovi sistemi di autenticazione per distinguere le immagini vere da quelle sintetiche. Tutti potranno diventare, potenzialmente, creatori di quantità infinite di arte. Oppure di ciarpame pseudoartistico senza originalità.
Fonti aggiuntive: Ars Technica, Ars Technica.