Pubblicazione iniziale: 2023/11/05 11:13. L’articolo è stato aggiornato estesamente dopo la pubblicazione iniziale per tenere conto di nuove informazioni. Ultimo aggiornamento: 2023/11/09 18:45.
I Beatles hanno rilasciato pochi giorni fa una nuova canzone,
Now and Then. È surreale che i Beatles escano con un brano nel 2023, ma
grazie al machine learning è possibile. Lasciando da parte la bellezza
del brano in sé e il suo valore emotivo, rimane la questione tecnica e quasi
filosofica di decidere se lo si possa considerare “autentico”, e più in
generale cosa voglia dire oggi questa parola.
Questo è il video ufficiale della canzone:
John Lennon aveva registrato una demo della propria voce, mentre cantava
questo brano, su una semplice audiocassetta, nel 1977, accompagnandosi al
pianoforte (questo dovrebbe essere un suo riversamento grezzo; fonte alternativa[2023/11/09: i link sono stati rimossi]). La voce di Lennon era in buona parte coperta dal pianoforte e prima d’ora era
impossibile filtrare o separare il pianoforte per recuperare solo la voce e
poi completare la canzone registrando oggi gli strumenti e le voci di
accompagnamento, come si fa di solito e come fu fatto nel 1995 per Free as a Bird, altra canzone dei Beatles che usa la voce di Lennon tratta da una demo registrata su audiocassetta.
Così i Beatles ancora in vita, Paul McCartney e Ringo Starr (Lennon fu ucciso nel 1980 e George Harrison è morto di malattia nel 2001), hanno deciso di
usare la tecnica di ricostruzione e demixing (isolamento e separazione dei singoli strumenti e delle voci, portandole su tracce separate) usata da Peter Jackson con grande successo per l’audio del documentario
Get Back (esempio).
Il procedimento è descritto nel video qui sotto, che spiega la genesi di Now and Then: l’audio originale di Lennon è ascoltabile brevemente a 3:04, 4:10 e 4:46; a 7:08 si sente la voce ricostruita, prima dell’aggiunta dell’accompagnamento musicale usato per il brano finale.
Come descritto in dettaglio in questo video, la demo originale di Lennon è stata inoltre accelerata leggermente, una porzione è stata rimossa ed è stata aggiunta una parte nuova che sfrutta dei cori tratti da altre canzoni dei Beatles, come Eleanor Rigby e Because.
I dettagli pubblicamente disponibili di questo procedimento di demixing sono scarsi, e per ora non ho trovato documentazione tecnica specifica su come è stato applicato a Now and Then. Però ho trovato questa intervista, che usa con molta circospezione i termini inglesi “generative” e “regenerative” (a partire a 8:53), e questo video e questo articolo di New Scientist (paywall; copia su Archive.is), che accennano a tecniche sottrattive. Tutte queste fonti sono dedicate a Get Back, ma sembra che la tecnica usata per il nuovo brano dei Beatles sia sostanzialmente la stessa, e nei video ufficiali dedicati a Now and Then si parla esplicitamente di machine learning e si nomina il software MAL usato per Get Back e gestito, per Now and Then, da Emile de la Ray, Hunter Jackson e Tyrone Frost, come indicato nei titoli di coda del secondo video incorporato qui sopra.
Da quel che ho capito, ci sono due scenari possibili:
Sottrazione: i suoni del pianoforte nella cassetta di Lennon sarebbero stati rimossi dando al software moltissimi campioni di suoni di pianoforti e addestrandolo a riconoscere e sottrarre solo quei suoni, lasciando quindi pulita la voce originale di Lennon, che sarebbe stata poi elaborata digitalmente con tecniche convenzionali.
Generazione: il software sarebbe stato addestrato su un gran numero di campioni di alta qualità della voce di Lennon e poi avrebbe usato l’audio registrato da Lennon sulla cassetta come
riferimento per aggiungere le frequenze mancanti o generare i suoni vocali corrispondenti in alta qualità,
attingendo ai campioni forniti, come nel modello di bandwidth expansion che potete ascoltare verso il fondo di questa pagina.
Qualche indizio sulla tecnica effettivamente usata può emergere da questo brano dell’articolo di New Scientist riferito a Get Back, che indica che i dati usati per addestrare la rete neurale includevano campioni di persone generiche che parlano e di strumenti suonati separatamente (non dai Beatles) e spezzoni dell’audio originale di Get Back nei quali i Beatles parlavano senza altri suoni estranei oppure suonavano i propri strumenti uno alla volta:
The team consulted with Paris Smaragdis at the University of Chicago and started to create a neural network called MAL (machine assisted learning), named after the Beatles’ longstanding road manager Mal Evans. The team also started to build a set of training data that was higher quality than datasets used in academic experiments.
This training data began as generic clips of people talking and instruments played separately that team members recorded themselves, roping in friends and colleagues. In time, the team added to this data with real sections of the 1969 audio in which the Beatles could be heard speaking alone or playing their instruments solo, to add specificity.
Se si tratta di pura sottrazione, allora mi sembra ragionevole dire che la voce che si sente è effettivamente quella di Lennon. Ma se i suoni
originali sono stati ricostruiti o sostituiti con suoni analoghi di migliore qualità, sia pure provenienti da campioni della voce di Lennon, si può
ancora parlare di voce autentica?
Comunque sia, il risultato all’ascolto è indiscutibilmente notevolissimo: emotivamente, la voce è quella di Lennon. Però mi sembra che
questa tecnica generativa, se è stata usata, rischi di sconfinare nel deepfake se non
addirittura nel falso. In questo caso era disponibile come riferimento una
registrazione di Lennon che cantava effettivamente quella canzone; ma quanto sono accurati i campioni che sostituiscono gli originali (nell’ipotesi di una generazione)? E cosa
impedisce di usare questa tecnica per far cantare a Lennon qualunque altro
brano?
Mi sembra insomma che ci sia una differenza tecnica e di principio fondamentale fra
ripulire ed elaborare una voce esistente, effettivamente registrata, e
sostituirne ogni singolo suono con un altro preso da un campionario, anche se
si tratta di campioni della voce del cantante originale.
Per fare un paragone, è come se si decidesse di restaurare il Colosseo usando
materiali dello stesso tipo degli originali, con tecniche di costruzione
identiche a quelle originali, per ridare all’edificio l’aspetto che aveva
prima di cadere in rovina. Sarebbe ancora un edificio autentico? È il paradosso della nave di Teseo in versione musicale.
L’intelligenza artificiale, di cui il machine learning è una
branca, sta cambiando il modo in cui pensiamo a concetti fondamentali come
vero e falso, autentico e sintetico. Credo sia importante fermarci a
riflettere se è questo il tipo di cambiamento che vogliamo, e come vogliamo
dirigerlo.
La campagna social “Open to Meraviglia” del Ministero del Turismo italiano, che già nel titolo rigurgita
una mostruosità linguistica, è chiaramente gestita da gente che ha qualche
difficoltà con i social e la pianificazione. Eppure la gente in questione è il
Gruppo Armando Testa, che si definisce
“il più grande gruppo italiano di comunicazione del mondo”, affiancato
da Almaviva, che si dichiara
“leader nell’Intelligenza Artificiale (AI), nell’analisi del linguaggio
naturale e nei servizi Big Data”.
I disastri che sono emersi man mano in questa campagna sono talmente tanti che
ho dovuto dividere questo articolo in capitoli per raccontare per bene una delle
figuracce più epiche nella storia della comunicazione digitale.
Capitolo 1. Il nick Venereitalia23 non registrato nei social
Sul sito del Gruppo Armando Testa, linkato sopra, viene detto che la
campagna digitale
“vivrà nel profilo Instagram venereitalia23, nel sito Italia.it e nelle
altre piattaforme social”.
Nel video promozionale creato per il Ministero del Turismo italiano si vede
ripetutamente che la Venere botticelliana animata digitalmente ha come account
social
Venereitalia23. E questo nome di account viene anche citato direttamente dalla voce di “Venere” nel video:
“su Instagram, Linkedin e tutti i social sarò Venereitalia23” (https://www.youtube.com/watch?v=EOw57LXR-_M).
Il 26 aprile il video è stato reso privato, ma nel frattempo ne ho scaricato una copia e ripubblico qui sotto gli screenshot pertinenti.
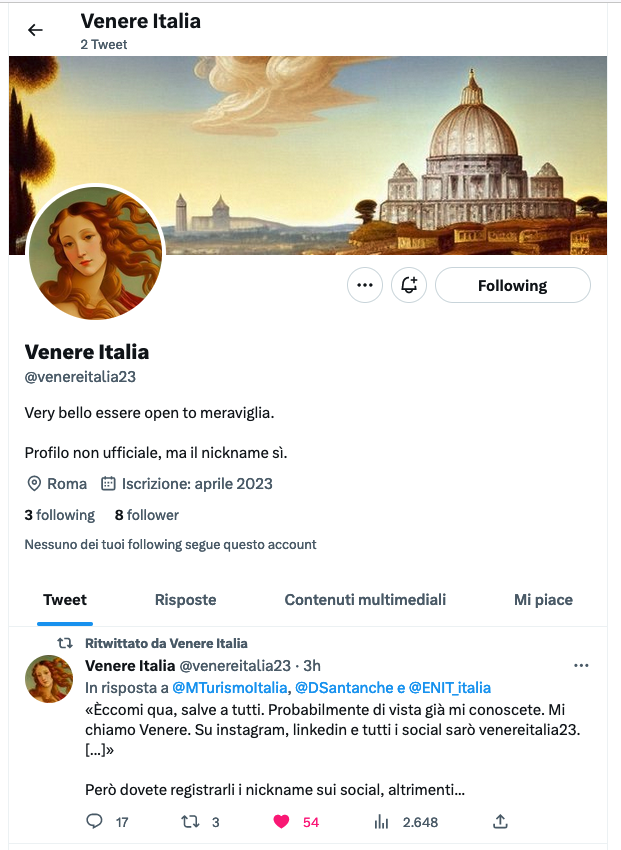
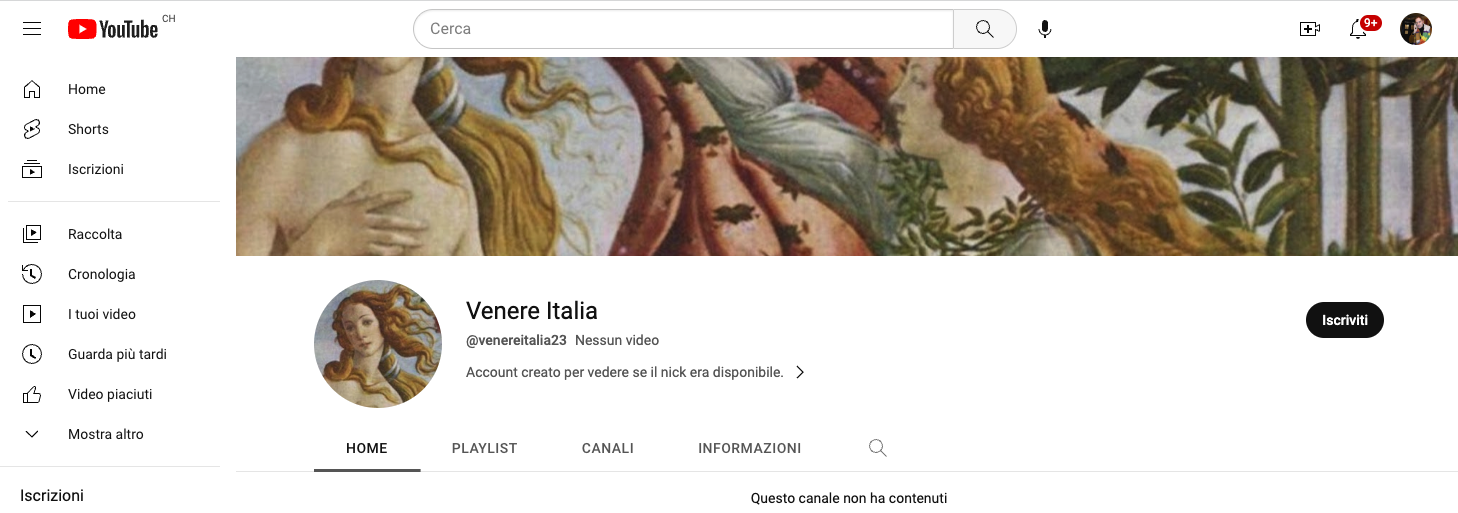
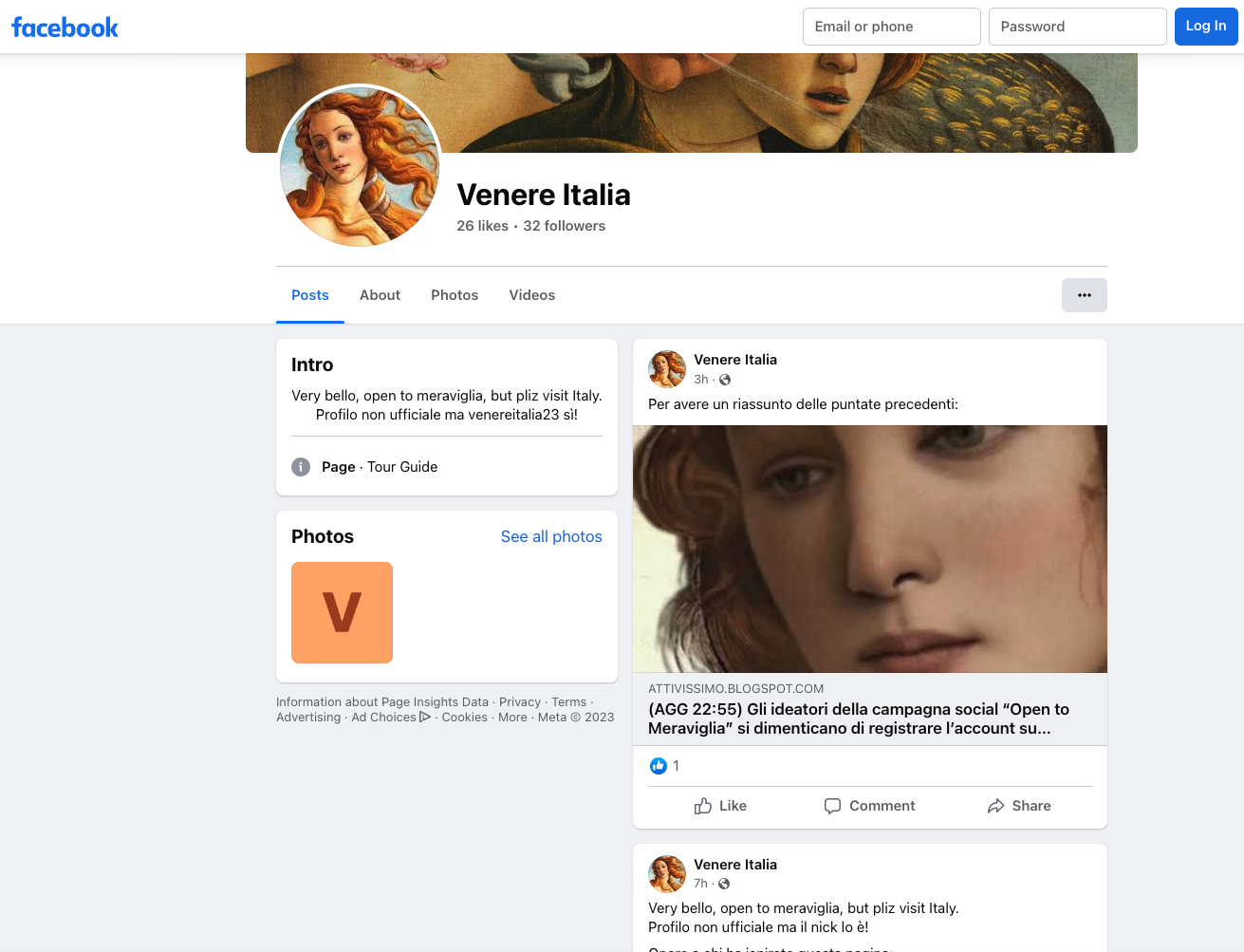
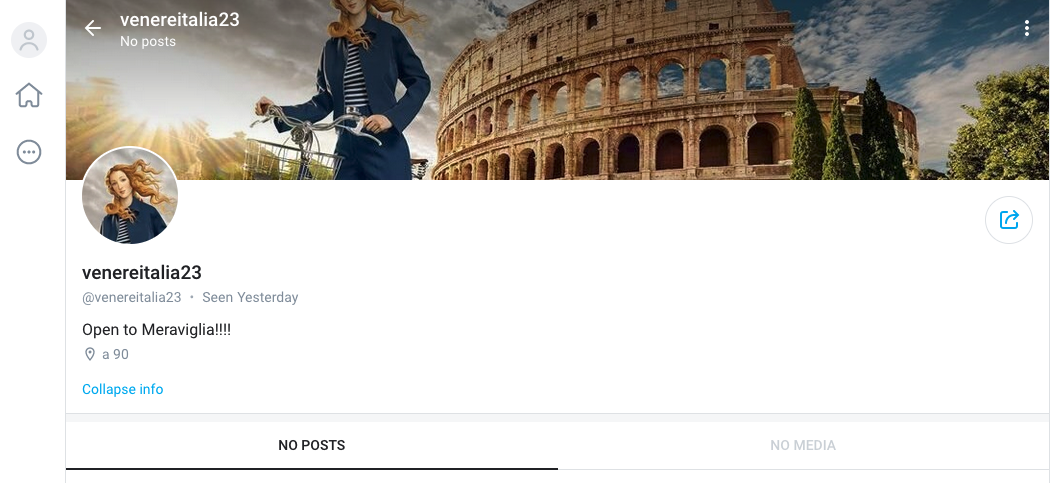
Beh, non sarà Venereitalia23 su proprio tutti i social. Infatti i coordinatori della campagna,
sbadatelli, si sono dimenticati di registrare il nome Venereitalia23 su
Twitter, YouTube e Facebook prima di avviare la campagna, come si dovrebbe invece fare per un’ovvia misura standard di brand protection. Lo ha fatto al posto loro qualcun altro.
Già con questo scivolone il divertimento è assicurato. Ma non è tutto.
Capitolo 2. Il nome di dominio “dimenticato”
A quanto risulta al momento, sembra che gli organizzatori della campagna si
siano dimenticati anche di registrarsi il nome di dominio italiano dello
slogan, ossia
Opentomeraviglia.it.
Secondo i dati pubblicamente consultabili di Whois, questo nome di dominio
risulta intestato attualmente a tale Filippo Giustini ed è attualmente un
redirect che porta alla società Marketing Toys in provincia di Firenze,
alla quale vanno i miei complimenti per la
“fantasia, intuizione, decisione e velocità d'esecuzione” (cit.;
grazie a
@i_poteri_forti
per la segnalazione del redirect).
Questo è un indicatore di un metodo di lavoro poco professionale, perché
WhatsApp normalmente applica una compressione fortissima alle immagini
scambiate e quindi è un pessimo metodo per inviare immagini destinate alla
pubblicazione su un sito. Nel frattempo, i nomi dei file sul sito del
Ministero sono stati cambiati.
Ma rispetto a un altro fatto bizzarro che è stato rilevato, tutto questo è
quasi trascurabile.
Capitolo 4. Le immagini dell’Italia girate in Slovenia
Successivamente è emerso che
alcune delle immagini che dovrebbero raffigurare le bellezze dell’Italia
sono in realtà state girate fuori Italia, in Slovenia, e sono riprese stock, secondo quanto segnala Selvaggia
Lucarelli (https://twitter.com/stanzaselvaggia/status/1650020739779555328).
Selvaggia Lucarelli su Twitter ha anche pubblicato il link al video stock su
Artgrid, consentendo a tutti di confrontare le immagini dello spot con quelle
di Artgrid e della cantina Čotar. Gli spezzoni video stock di Artgrid sono
intitolati Wine Tasting with Friends (https://artgrid.io/story/26708/wine-tasting-with-friends
; https://cotar.si/).
Nelle anteprime di questi spezzoni se ne notano alcune che mostrano
esattamente la stessa ambientazione, la stessa inquadratura e le stesse
persone presenti nel video a 27 secondi dall’inizio.
La pagina delle anteprime degli spezzoni video su Artgrid. Notate l’ultima
riga in basso.
Dettagli dell’anteprima centrale dell’ultima riga.
Fotogramma del video ufficiale a 27 secondi dall’inizio.
I lettori mi segnalano che Triesteprima.it ha confermato la localizzazione
slovena delle riprese:
“La scena della cantina in cui brinda un gruppo di amici è stata infatti
girata da Cotar a Gorjansko, a pochi chilometri da Trieste. Non solo, come
rivelato dal produttore e regista triestino dell'agenzia creativa Terroir
Films, Massimiliano Milic, che ha reso pubblica la gaffe del Ministero, la
clip è stata presa da Artgrid, un archivo stock, ed è firmata da Hans Peter
Scheep. "Me ne sono accorto perché, scorrendo le immagini del filmato, ho
visto persone che conosco. Inoltre ho riconosciuto sia la corte che
l'etichetta di Cotar", spiega Milic.”
(https://www.triesteprima.it/cronaca/open-to-meraviglia-spot-slovenia-.html).
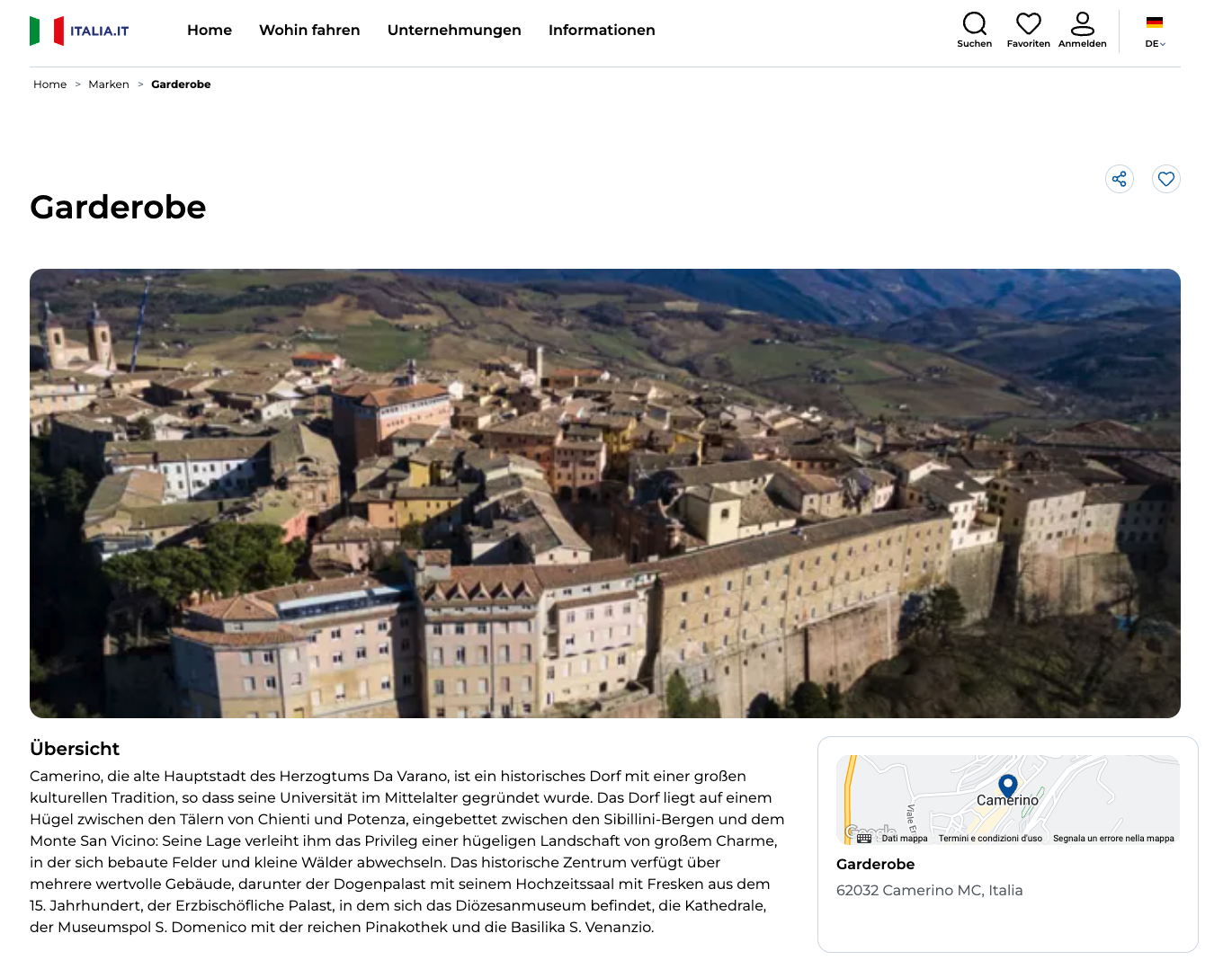
Capitolo 5. La città di Brindisi diventa Toast, Camerino diventa Garderobe e
Sutera diventa Homosexuell
La farsa non finisce qui. Sempre Lucarelli
segnala
che il sito ufficiale della campagna Open to Meraviglia, ossia
Italia.it, ospita traduzioni in tedesco nelle quali
sono stati tradotti letteralmente i nomi delle località, per cui
Brindisi è diventata Toast, Fermo è diventa Stillstand, Prato è
diventata Rasen, Cento è diventata Hundert, Scalea è diventata
Treppe, e Camerino è diventata Garderobe, e così via.
Screenshot della pagina dedicata a Garderobe (Camerino) su Italia.it.
Le traduzioni, se così si possono chiamare, sono opera della società Almawave,
che il 9 febbraio 2023 se ne era vantata in un comunicato stampa con queste parole fatidiche (ho
aggiunto io il grassetto):
Almawave S.p.A, società del Gruppo Almaviva, quotata sul mercato Euronext
Growth Milan (Ticker: AIW), leader nell’Intelligenza Artificiale (AI),
nell’analisi del linguaggio naturale e nei servizi Big Data, si è aggiudicata
la gara indetta dal Ministero del Turismo relativa alla fornitura di
tecnologie di machine translation (traduzione automatica), basate
sull’Intelligenza Artificiale.
Il contratto, della durata di tre anni, permetterà la traduzione multilingua
dei contenuti del sito ufficiale del turismo italiano www.italia.it.
Grazie alle tecnologie di AI e ai modelli di machine translation del Gruppo
Almawave, opportunamente addestrati e integrati con servizi professionali
per garantirne la massima qualità, il Ministero del Turismo potrà disporre di un servizio di traduzione
automatizzata di tutte le notizie e informazioni che saranno pubblicate sul
portale. Le lingue abilitate saranno l’inglese, lo spagnolo, il francese, il
tedesco e il portoghese.
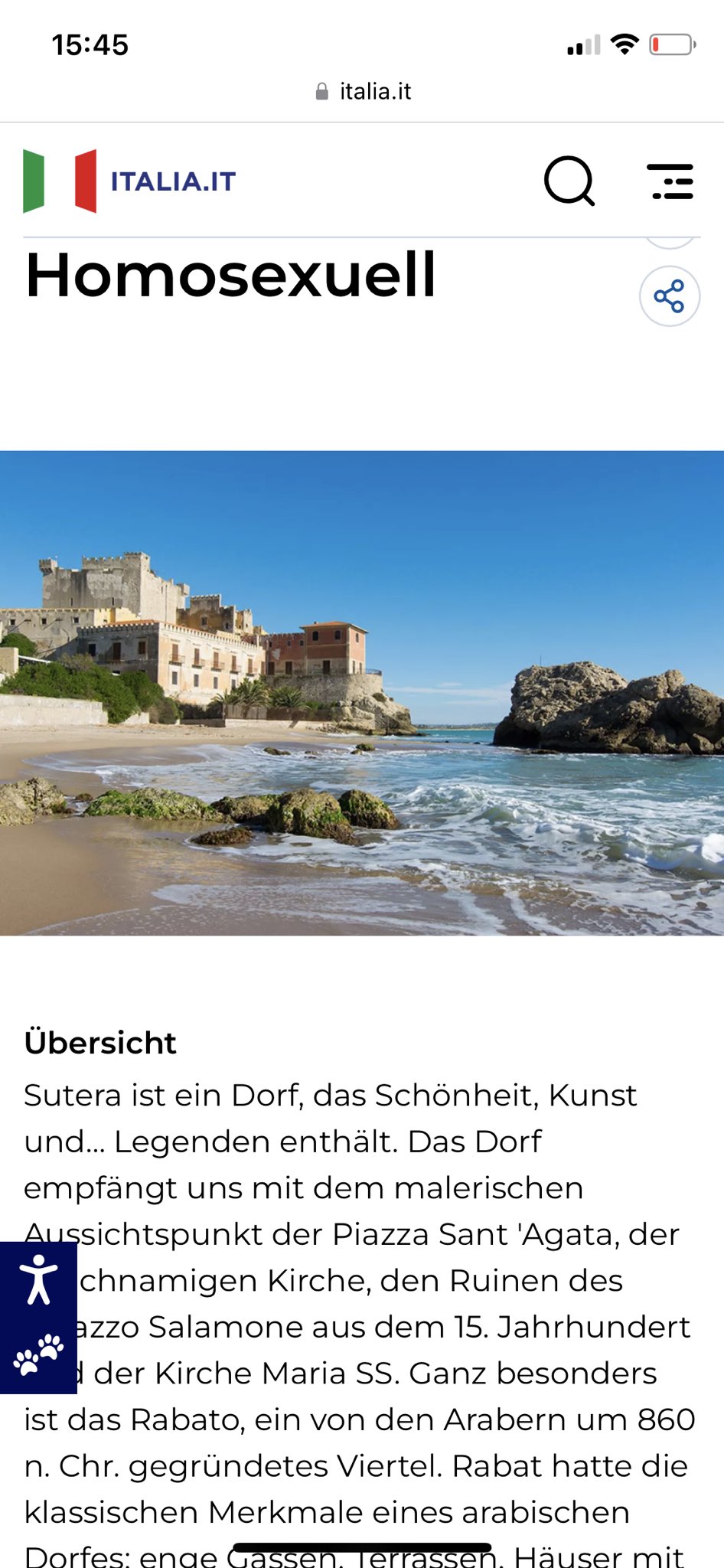
Lucarelli non ha pubblicato i link alle pagine specifiche, ma li aggiungo io
qui sotto, insieme ad altre località trovate dai lettori, fra le quali spicca
un assolutamente epico Homosexuell come traduzione di “massima qualità”
del nome della località sicula Sutera (grazie
Adriano; grazie
La Regione Ticino).
Ho incluso anche i link alle copie permanenti di queste perle e ho
riordinato il tutto in ordine alfabetico tedesco:
Fortunatamente, Lecco,
Troia e Bellano non
figurano tra le traduzioni letterali in tedesco.
Nelle ore successive alla diffusione della notizia di questi disastri
linguistici, che hanno tutti i segni di una tipica traduzione fatta da un
software di intelligenza artificiale usato senza la minima revisione da parte
di una persona linguisticamente competente, dal sito Italia.it è scomparsa
completamente l’opzione di scelta della lingua tedesca e le pagine sono
diventate inaccessibili. Ma Internet non dimentica e le copie d’archivio
persistono.
Prima...
... e dopo.
Adriano Pedrana
ha salvato su Archive.org l’elenco completo dei link ora rimossi:
Nella versione inglese, invece, spiccano errori madornali come
italian e italians scritto in minuscolo. In inglese tutti i
sostantivi e aggettivi riferiti alle lingue e ai popoli vanno in maiuscolo: è
una nozione da scuola media. Si scrive, per esempio,
Do you speak English? Are you French? (https://www.italia.it/en;
https://www.italia.it/en/open-to-meraviglia).
Capitolo 6. Gli errori nel testo
Bufale un tanto al chilo nota che è sbagliata l’affermazione fatta nel video, ossia che l’Italia sia “lo 0,5% della superficie terrestre”. Il valore reale è meno della metà, ossia lo 0,2%.