La settimana scorsa sono stato alla Starcon di Bellaria, dove come consueto ho
fatto da traduttore per gli attori ospiti di questo raduno di appassionati di
fantascienza e fantastico. È andato tutto benissimo con due dei tre ospiti:
Ricky Dean Logan ("Data" in
Ritorno al Futuro 2) e
Richard Brake (Re della
Notte in Trono di spade, generale Valin Hess in
The Mandalorian).
Con Ricky Dean Logan.
Con Richard Brake.
Con il terzo, Peter Weller (Robocop), è andata un po’ diversamente.
Visto che fra i partecipanti alla Starcon, nei social network e nei media in
generale girano varie versioni su cosa sia successo, scrivo qui due righe di
chiarimento.
Sabato 13 e domenica 14 Weller ha insistito per parlare in
italiano in entrambe le sue apparizioni sul palco. Normalmente, invece, gli
ospiti stranieri parlano in inglese e io traduco subito dopo in italiano quello che
hanno detto. Questo permette a tutto il pubblico presente di seguire: sia chi
capisce solo l’italiano, sia chi sa solo l’inglese perché arriva alla Starcon
da fuori Italia.
Ma Weller non si rende conto che il suo italiano è buono ma lacunoso e alla
lunga poco comprensibile e difficile da seguire (“estenuante” è l’aggettivo azzeccatissimo usato da una persona presente). Per la sua prima apparizione sono stato accanto a
lui sul palco, a sua disposizione. Mi ha chiesto a bruciapelo come si dicessero in italiano alcuni
termini e glieli ho detti. Ma ha fatto un misto continuo di italiano e inglese,
senza fermarsi per lasciarmi il tempo di tradurre o per correggere le parole
italiane che spesso usava a sproposito.
Peter Weller.
Oltretutto, durante questa sua prima apparizione si è interrotto per tirar
fuori il telefonino e far partire una sessione Zoom per dei suoi conoscenti
(la sessione non riguardava la sua apparizione sul palco). Piuttosto cafona,
come cosa: sarebbe stata assolutamente delegabile. Un dettaglio che dal pubblico non si sarà notato è che ha lasciato attiva quella
sessione Zoom, con il volume alto, rimettendo il telefono in tasca. Io
ero accanto a lui, che cercavo di infilare qualche correzione alle sue parole
italiane sbagliate, con il baccano di gente sconosciuta che conversava
attraverso il suo telefonino. Riuscivo a malapena a sentire cosa diceva Weller. Un disastro, soprattutto per il pubblico.
La sua apparizione sul palco è risultata ben poco comprensibile per chiunque non
fosse bilingue. Un po' di gente, dopo l'evento, si è lamentata in privato e online di non aver
capito molti passaggi dei discorsi di Weller.
Io non c'ero al panel di oggi,ma ieri sì ed è stata l'unica volta che me ne sono andata prima della fine di un incontro. Mi dispiace davvero per te! Alla Starcon ho sempre visto gente interessante, più o meno simpatica, ma lui non è stato né interessante né, tantomeno, simpatico
— TheProffa aka La Pam 🦉#Antifascista sempre (@mammapam) May 14, 2023
Paolo, io ho provato a seguire, ma non riuscivo e ne ne sono andato.
Grazie comunque per tutto quello che fai, per gente come me.
Così prima della sua seconda apparizione gli ho detto in privato che c'erano state delle
lamentele e che per la comprensibilità del suo intervento, non certo facilitata dall’impianto audio pessimo, era meglio
che lui lo facesse nella sua lingua madre e io lo traducessi in italiano. Si è rifiutato e ha detto categoricamente
che avrebbe fatto l'intervento in italiano (o meglio, in quello che secondo lui è italiano). Secondo lui io
sarei dovuto restare sul palco a sua disposizione per dirgli la traduzione delle
parole che non conosceva in italiano.
Gli ho spiegato educatamente che così non si può
lavorare (perché se lui dice una cosa sbagliata in italiano lo devo fermare e
correggere). Ho ribadito che il suo intervento, fatto come lo voleva fare
lui, non sarebbe stato comprensibile per il pubblico. Non ha voluto sentir ragioni e quindi
gli ho detto “I’m an interpreter. I can’t work like this. The stage is
yours” e gli ho indicato il palco.
Lui ha risposto “Then go” (non nel tono di “vattene”, come hanno capito alcuni). Me ne sono andato, mi sono seduto fra il pubblico e ho
ascoltato il suo intervento. È stato un minestrone di italiano e inglese
(con intere frasi in inglese), di parole italiane sbagliate (“lamentazione” al
posto di “lamentela”, “registrazioni” al posto di “lista di nozze”, quel misterioso “gianchi” ficcato ripetutamente nelle frasi in italiano che era “tossicodipendente”, ossia “junkie”, eccetera). Dal palco Weller ha detto che io me ne ero andato via perché ero
“arrabbiato”. Ho alzato la mano e gli ho detto ad alta voce “I’m still here”, anche per far capire al pubblico che non ero misteriosamente assente ma che avevo deciso di non partecipare a questa pagliacciata istrionica.
Risultato: Weller non capiva le
domande del pubblico, che ovviamente gli venivano fatte in italiano. Ha parlato pochissimo di fantascienza, dicendo oltretutto che gli fa abbastanza schifo, cosa un tantinello offensiva verso un pubblico composto da appassionati del genere fantascientifico. Ha chiesto al suo pubblico, composto quasi completamente da italiani, se
conoscevano Dante. Peggio ancora, ha chiesto a noi Trekker se sapevamo chi
fosse J.J. Abrams.
Prevengo una domanda quasi inevitabile: sì, esiste una registrazione
audio e video degli interventi, ma al momento non è previsto che venga pubblicata. Chi c’era sa com’è andata.
Non me la sono presa; sono abituato a gestire gente che è talmente piena di sé da non capire quando sta trattando gli altri come pezze da piedi (come ha fatto Weller con tutto il pazientissimo staff della Starcon) e ho il privilegio di poter dire a queste persone quello che penso di loro e dei loro comportamenti senza dover rendere conto a nessuno tranne il pubblico, perché ho scelto di fare queste traduzioni a titolo gratuito, come volontariato (come fa tutto lo staff della convention).
Mi dispiace per il
pubblico, che avrà perso buona parte del senso di quello che Weller diceva,
solo perché l’attore non ha voluto accettare la critica costruttiva di un
traduttore professionista e ha voluto fare la primadonna. Cosa che, in effetti, gli è riuscita benissimo. Fine della storia.
È disponibile subito il podcast di oggi de Il Disinformatico della
Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto: lo trovate presso
www.rsi.ch/ildisinformatico
(link diretto) e qui sotto.
Più di quarant’anni fa, lo scrittore di fantascienza e futurologo Arthur C.
Clarke scrisse, nel suo libro Profiles of the Future,
parole
sottilmente sprezzanti e profetiche a proposito della musica generata tramite
computer:
“[...] ora che ai calcolatori elettronici è stato insegnato come comporla,
possiamo aspettarci fiduciosamente che ben presto alcuni di questi calcolatori
impareranno ad apprezzarla, evitandoci così lo sforzo”.*
* “The prospect for modern music is a little more favourable; now that
electronic computers have been taught to compose it, we may confidently
expect that before long some of them will learn to enjoy it, thus saving us
the trouble”.
[CLIP: HAL si offre di cantare una filastrocca in 2001 Odissea nello spazio]
Sembra che Clarke ci abbia azzeccato ancora una volta: dopo la musica
sintetica generata dall’intelligenza artificiale, è ora il turno degli
ascoltatori sintetici.
Pochi giorni fa è emersa la notizia che la piattaforma
di streaming audio Spotify ha rimosso dal proprio catalogo decine di migliaia
di brani musicali che erano stati generati usando
Boomy, un servizio di generazione di musica
basato sull’intelligenza artificiale. Spotify ha inoltre bloccato temporaneamente la
pubblicazione di nuovi brani provenienti da Boomy.
Questi brani sono stati rimossi perché sospettati di essere ingredienti di una
frode di “streaming artificiale”. In pratica, gli account Spotify che consumavano
questi brani non erano persone reali che ascoltavano musica: erano programmi che fingevano di essere
ascoltatori, allo scopo di far salire artificialmente il numero di ascolti di brani spazzatura e generare incassi
fraudolenti.
Va chiarito, fra l’altro, che Boomy è estranea alla frode ed è soltanto uno strumento usato
dai truffatori, tanto che Spotify ha
riattivato
la pubblicazione supervisionata di nuovi brani provenienti da questo servizio
di generazione musicale.
La notizia di questo blocco di massa ha fatto scalpore, ma in realtà non è il primo caso del suo genere: il meccanismo della truffa è già noto da tempo, ma secondo le ricerche del sito specializzato Music Business Worldwide è in rapida crescita a causa di tre fattori concomitanti.
Il primo fattore è la recente possibilità di generare a costo bassissimo o nullo un numero enorme di brani musicali, grazie appunto a servizi come Boomy, che dichiara di aver generato per i suoi utenti oltre 14 milioni di tracce musicali. Questo riduce enormemente i costi operativi della frode, perché prima era necessario prendere una persona e farle comporre qualcosa che somigliasse a un brano musicale. E quella persona, ovviamente, doveva essere pagata: poco, ma pagata.
Il secondo fattore è il successo delle cosiddette stream farm, che sono delle organizzazioni illecite che usano dei software basati sull’intelligenza artificiale per simulare il comportamento di un ascoltatore di musica in carne e ossa e coordinano le attività di un numero elevatissimo di questi ascoltatori sintetici per gonfiare il numero di ascolti dei brani spazzatura.
Il terzo fattore, quello decisivo secondo Music Business Worldwide, è l’attuale criterio di distribuzione dei compensi dei servizi di streaming audio, denominato “pro-rata”. In pratica, i soldi che ciascun abbonato paga mensilmente a Spotify, Apple Music o altri servizi analoghi confluiscono in un unico conto generale. Questo totale viene poi distribuito agli artisti e alle etichette musicali in base alla loro rispettiva quota di mercato. Più un brano è alto in classifica, più soldi incassa. E qui sta il problema: questo metodo di distribuzione incentiva gli utenti commerciali del servizio di streaming, cioè quelli che producono la musica, a cercare di ottenere il numero più alto possibile di ascolti (reali o simulati) invece del maggior numero possibile di ascoltatori.
La differenza può sembrare sottile, ma ha un effetto cruciale: con questo criterio pro-rata,parte dei soldi che ciascun abbonato paga per il servizio viene versata a brani che quell’abbonato non ha ascoltato e che spesso non sono stati ascoltati da nessuno, perché il loro piazzamento nella graduatoria dei compensi è stato ottenuto illecitamente usando le stream farm. Variefontistimano che questa frode porti via ai servizi di streaming circa un miliardo e duecento milioni di dollari l’anno, sui 17 miliardi e mezzo incassati dallo streaming musicale in tutto il mondo nel 2022, secondo i dati IFPI. E i vari filtri utilizzati dai servizi di streaming per identificare i brani generati dall’intelligenza artificiale e bloccarli sono imperfetti e insufficienti.
Esiste però un rimedio a questo problema, che toglierebbe di colpo l’ossigeno alle frodi di questo tipo: passare a un criterio in cui i soldi dell’abbonamento di un utente vengono dati esclusivamente agli artisti ascoltati da quell’utente. È il modello che SoundCloud, per esempio, chiama fan-powered, e che altri servizi di streaming stanno iniziando ad adottare. In questo modello non c’è un gruzzolo comune di soldi altrui accessibili ai truffatori, e quindi le stream farm e i loro brani musicali fittizi non hanno più motivo di esistere.
Il problema, insomma, è serio, e non potrà che peggiorare con il maturare dei software di generazione di musica sintetica tramite intelligenza artificiale, perché i brani falsi saranno sempre più difficili da distinguere da quelli autentici. Ma una soluzione, volendo, c’è.
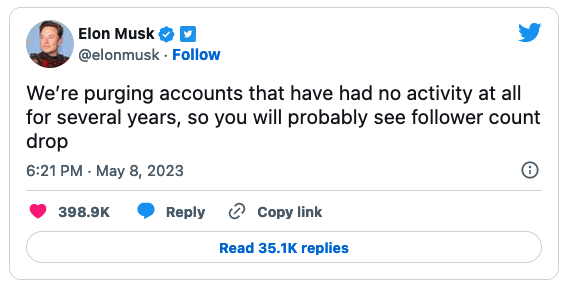
Elon Musk ha
annunciato
pochi giorni fa un nuovo cambiamento di Twitter molto controverso: gli account
che non hanno avuto alcuna attività per vari anni verranno eliminati e i loro
nomi torneranno a essere disponibili.
La “purga”, per citare il termine usato da
Musk (“We’re purging accounts that have had no activity at all for several years,
so you will probably see follower count drop”), è già in corso, e stando ad alcuni
tweet di
Elon Musk risalenti a dicembre 2022 potrebbe riguardare addirittura un miliardo e mezzo di
account che per anni non hanno pubblicato tweet e non hanno fatto login (“Twitter will soon start freeing the name space of 1.5 billion accounts”;
“These are obvious account deletions with no tweets & no log in for
years”).
Ma questa decisione comporta dei problemi tecnici e umani notevoli. Utenti
Twitter di spicco, come
John Carmack,
famosissimo sviluppatore di videogiochi fondamentali come
Wolfenstein 3D, Doom e Quake, hanno
chiesto
a Musk di ripensarci:
I may be reading this incorrectly, but if you are actually deleting inactive
accounts and all their historic tweets, I would STRONGLY urge you to
reconsider.
Letting people know how many “active” followers they
have is good information, but deleting the output of inactive accounts would
be terrible. I still see people liking ten year old tweets I made, but the
threads are already often fragmented with deleted or unavailable tweets. Don’t
make it worse!
Some may scoff at any allusion between Twitter and
ancient libraries, but while the burning of the library of Alexandria was a
tragedy, scrolls and books that were tossed in the trash just because nobody
wanted to keep them are kind of worse.
Save it all!
Eliminare gli account che sono inattivi da diversi anni significa infatti
cancellare interi pezzi di storia di Internet, rendendo illeggibili tante
conversazioni importanti fatte su Twitter negli anni scorsi. Significa anche
che gli account Twitter delle persone decedute verranno brutalmente
cancellati, privando i familiari del ricordo delle parole scritte e delle
immagini pubblicate da chi non c’è più. Rischiano di sparire anche tutti i contenuti pubblicati negli
account delle persone famose non più in vita, con milioni di follower (Chadwick Boseman, per esempio).
Il problema è delicato anche per le aziende che non esistono più e per le
tante persone famose ancora in vita che hanno smesso di usare Twitter negli
anni scorsi e non vi scrivono più nulla: stando a quello che ha dichiarato
Elon Musk, i loro account verrebbero eliminati e i loro nomi utente
tornerebbero disponibili, con un evidentissimo rischio di furto di identità e di creazione
di equivoci e di impostori molto credibili.
Twitter non ha pubblicato dettagli tecnici su come e in quanto tempo verrà
effettuata questa eliminazione di massa: se si scrive all’indirizzo di mail
riservato alla stampa, ossia press@twitter.com, da
marzo scorso
si ottiene come unica risposta automatica l’emoji dell’escremento. Cosa di cui Musk sembra andare orgoglioso, visto che ha annunciato l’introduzione di questo
comportamento a marzo scorso con un apposito
tweet
(“press@twitter.com now auto responds with💩”).
Tutto quello che si sa, per ora, è che Musk ha
dichiarato
che “gli account verranno archiviati”, ma non si sa come verrà fatta
questa archiviazione, se i tweet archiviati saranno consultabili e quali
saranno gli effetti sui tweet incorporati o embeddati nelle pagine Web
per citarli.
Musk ha inoltre
aggiunto
che “è importante liberare i nomi utente abbandonati” (gli
handle
o username sono i nomi utente, ossia quelli che iniziano con il simbolo
della chiocciolina, e non vanno confusi con i display name). Si sa
anche che pochi giorni fa sono cambiate in sordina le
Norme sugli account inattivi
di Twitter:
prima
dicevano che era necessario fare almeno un login ogni sei mesi, ma adesso
dicono che bisogna “effettuare l'accesso almeno ogni 30 giorni”.
C’è insomma poca chiarezza, e la questione diventa particolarmente urgente per
i tanti casi in cui una persona è deceduta senza lasciare le credenziali di
accesso dell’account ai propri eredi, che quindi non possono neanche
effettuare un accesso periodico per tenere attivo quell’account in modo
fittizio e sottrarlo alla purga. Twitter per ora non ha annunciato nessuna opzione per
trasformare un account facendolo diventare commemorativo, come si fa da tempo
per esempio su
Facebook.
Se volete salvare dall’eliminazione un account Twitter inattivo, conviene che vi
muoviate in fretta. Se avete i codici di accesso all’account, potete
scaricarne una copia completa seguendo le
istruzioni
pubblicate sul sito di Twitter. Potete poi
caricare
questa copia su Archive.org oppure passare da
Tweetarchivist.com o
Tinysubversions.com
per renderla pubblicamente consultabile.
Se invece non avete la password di un account, potete usare dei servizi a
pagamento, come
Twtdata, per scaricare
una copia di tutti i tweet pubblici di un utente, oppure immettere
twitter.com/nomeutente nella casella Wayback Machine di
Archive.org. Questo vi permetterà di sfogliare le copie archiviate automaticamente dei tweet pubblici
di quell’utente. Non è un rimedio perfetto, ma è meglio di niente.
Prendete il vostro smartphone, se potete, e usatelo per visitare una qualsiasi
pagina del Web: noterete che a sinistra del nome del sito che state visitando
c’è l’icona di un lucchetto. Sapete spiegare che cosa significa quel lucchetto?
Se avete risposto che indica che il sito che state guardando è sicuro e
affidabile, avete sbagliato, ma consolatevi: la maggior parte della gente
sbaglia allo stesso modo. Secondo uno
studio condotto da Google
nel 2021, solo l’11% delle persone conosce il vero significato di quest’icona,
e anzi molti utenti non sanno neppure che quest’icona è cliccabile. Anche altri
studi hanno
confermato la
diffusione molto ampia di questo equivoco. Ed è per questo che Google ha
annunciato
che ai primi di settembre 2023 l’icona del lucchetto verrà sostituita da un altro
simbolo in Chrome per dispositivi Android e sparirà del tutto su Chrome per iPhone e iPad.
È un cambiamento importante, che rispecchia il cambiamento altrettanto grande
che ha coinvolto tutta Internet negli ultimi anni. L’icona del lucchetto
indica che il sito viene visitato usando una connessione cifrata e quindi i
dati che vengono scambiati non sono intercettabili o alterabili da parte di
terzi. Una funzione preziosa, per esempio, per qualunque sito che gestisca
dati personali o soldi, come i siti di acquisti o di gestione dei conti
bancari.
Questa connessione cifrata, indicata dalla sigla HTTPS, è stata introdotta
oltre vent’anni fa, ma è rimasta a lungo una rarità e veniva appunto segnalata come una
protezione aggiuntiva da tutti i browser, da Internet Explorer a Safari,
grazie all’icona del lucchetto. Ma oggi la connessione cifrata è diventata la
norma, per cui quest’icona è quasi sempre presente sullo schermo e quindi ha
perso la propria utilità informativa: anzi, secondo Google è diventata
pericolosa, perché oggigiorno anche i siti dei truffatori
offrono connessioni
cifrate e quindi fanno comparire sullo schermo il lucchetto. Lo fanno perché
contano sul fatto che moltissimi utenti penseranno che il lucchetto sia un
indicatore di autenticità o affidabilità. Ma non lo è affatto.
Se usate Google Chrome, insomma, preparatevi al fatto che tra poco l’icona del
lucchetto verrà sostituita, sui computer e sui tablet e smartphone Android, da
un simbolo molto differente: due cerchietti e due trattini, che dovrebbero
rappresentare delle regolazioni o impostazioni. L’icona sarà cliccabile per
avere maggiori informazioni sul sito visitato e sulla protezione delle
comunicazioni con quel sito, esattamente come prima. Sui tablet e smartphone
Apple, invece, l’icona sparirà completamente. E visto che Chrome è uno dei
browser più usati e quello che fa Chrome fa tendenza, è probabile che anche le
altre app di navigazione adotteranno presto un cambiamento analogo [in Firefox c’è già un’icona molto simile ma speculare, che ha una funzione differente: informa sui permessi e i cookie concessi a un sito].
Il simbolo che sostituirà il lucchetto in Google Chrome da settembre.
Preparatevi insomma per questo cambiamento a settembre, e nel frattempo
ricordate che già adesso l’icona del lucchetto, in qualsiasi browser, non
indica che un sito è autentico o fidato, ma significa soltanto che la
comunicazione con quel sito è protetta dalla crittografia. Vuol dire
che magari state comunicando con dei truffatori, ma lo state facendo in
maniera protetta. Magra consolazione, lo so: forse sarebbe meglio non comunicare
affatto con certa gente.
Sto collaborando a un’inchiesta sulle tecniche dei criminali che organizzano i cosiddetti romance scam, quei crudelissimi raggiri nei quali il truffatore contatta la vittima fingendo di essere interessato a una relazione sentimentale via Internet e poi, a distanza di qualche tempo dall’inizio della relazione, chiede soldi per risolvere un suo guaio personale (inventato), facendo partire una truffa che può costare carissimo e lascia ferite emotive profondissime.
Se siete stati vittime (maschili o femminili) di questi criminali e volete raccontare la vostra storia con il massimo anonimato, contattatemi via mail a paolo.attivissimo@rsi.ch oppure su Instagram (instagram.com/disinformatico) o Telegram (t.me/il_Disinformatico). Se conoscete qualcuno che ha subìto questi inganni e potrebbe essere disposto a parlarne per salvare altre persone, informatelo di questo mio invito. Grazie.
È disponibile subito il podcast di oggi de Il Disinformatico della
Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto: lo trovate presso
www.rsi.ch/ildisinformatico
(link diretto) e qui sotto.
Buon ascolto, e se vi interessano il testo di accompagnamento e i link alle fonti di questa puntata, sono qui sotto.
---
[CLIP: Rumore ambientale di ufficio postale UK]
Questa storia inizia nel Regno Unito, nel 1999, anno di sofferenza e di
insonnia per tanti informatici, ma non riguarda il famigerato Millennium Bug.
È l’anno in cui le Poste britanniche iniziano ad installare un nuovo sistema
di contabilità informatizzata, denominato Horizon, destinato a gestire
i milioni di transazioni che hanno luogo ogni giorno nei numerosissimi uffici
postali del paese, che sono un servizio fondamentale per la collettività: come
avviene in tanti paesi, i cittadini li usano per fare pagamenti, riscuotere
pensioni e fare piccoli acquisti, insomma per muovere quantità notevoli di
denaro oltre che per ricevere e spedire corrispondenza.
Il signor Alan Bates è un cosiddetto sub-postmaster: dirige una delle
tantissime succursali delle Poste britanniche, quella di Craig-y-Don, nel
Galles. Un anno dopo l’introduzione del sistema Horizon, Alan Bates segnala
formalmente alle Poste che il sistema ha dei problemi: crea degli ammanchi che
in realtà non esistono. Nel frattempo ci sono già state sei condanne di altre
persone per frodi registrate dal sistema, ma secondo Bates si tratta invece di
errori del software, che è prodotto dalla Fujitsu. Le Poste britanniche negano
e nel 2003 rescindono il loro contratto con Alan Bates.
Questo è l’inizio della
storia
di uno dei più gravi casi di errore giudiziario legato all’informatica di cui
si abbia notizia. Durerà oltre vent’anni e porterà a centinaia di condanne
ingiuste, con incarcerazioni, diffamazioni, divorzi e suicidi delle persone
additate per errore, dal software e dalla giustizia, come ladri e truffatori,
ed è un caso esemplare di eccessiva fiducia nell’infallibilità dei computer
che va conosciuto per evitare che si ripeta altrove.
Benvenuti alla puntata del 5 maggio 2023 del Disinformatico, il podcast
della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane
dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Per un computer, fare calcoli con i numeri è una funzione basilare. Niente a
che vedere con le complessità delle simulazioni di fisica o dell’intelligenza
artificiale. Sembra quindi impossibile, a prima vista, che una grande azienda
come Fujitsu e una grande organizzazione come il servizio postale di un paese
possano realizzare e implementare un sistema informatico che
sbaglia a fare i conti. Eppure è successo, e con un sistema costato un
miliardo di sterline dell’epoca, ossia circa 2 miliardi e mezzo di franchi o
euro di oggi.
Oltre 700 gestori di filiali delle poste britanniche hanno ricevuto condanne
penali per frode contabile e furto, perché il software difettoso di Fujitsu
faceva sembrare che togliessero soldi dalla cassa. Migliaia di altri gestori
hanno dovuto pagare somme ingenti alle Poste britanniche per coprire gli
ammanchi di cui erano accusati. Fra il 2000 e il 2014, le Poste britanniche
hanno portato in tribunale 736 di questi gestori: in media un gestore a
settimana. Alcuni sono finiti in carcere, addirittura durante la gravidanza,
come è successo a
Seema Misra,
condannata per furto e messa in prigione nel 2010 quando aspettava il secondo
figlio, additata dalla stampa locale come “la ladra incinta”, ma
completamente scagionata dieci anni dopo. Altri sono finiti sul lastrico e
hanno anche dovuto affrontare il disprezzo delle proprie comunità, che li
vedevano come persone disoneste che avevano violato la loro fiducia in un
ruolo così centrale. Qualcuno, tragicamente, si è tolto la vita.
Nel 2014, a distanza di quindici anni dall’introduzione del software Horizon e
cinque anni dopo che un gruppo di questi sub-postmaster che avevano
subìto gli errori di Horizon aveva costituito un’associazione per chiedere
giustizia, arrivando poi all’attenzione dei media[in particolare
ComputerWeekly]
e in tribunale, finalmente una perizia tecnica indipendente ha dimostrato che
il software sbagliava davvero, e creava davvero ammanchi di cassa inesistenti.
Le Poste britanniche hanno risposto subito che
“non esiste assolutamente alcuna prova di problemi sistematici con il
sistema informatico”
e si sono autoassolte. Il governo britannico, unico azionista delle Poste, si
è rifiutato di pagare qualunque risarcimento o indennizzo. Ci sono voluti
altri anni, e altre azioni legali costosissime per gli accusati, per arrivare
a un risarcimento e all’annullamento di centinaia di condanne infondate.
Nel 2019 la
High Court of Justice, l’Alta corte di giustizia britannica, ha confermato che il software era
difettoso ed era rimasto tale per ben dieci anni e che questi difetti potevano
creare gravi errori contabili. Questa conferma è emersa grazie alla tenace
azione legale collettiva condotta contro le Poste britanniche da Alan Bates:
la stessa persona che quasi vent’anni prima aveva cercato inutilmente di
avvisare del problema. Ma la vicenda, ancora oggi, non si è ancora conclusa.
Con i computer non si discute
La situazione dei gestori accusati di frode era disastrosa. Loro, comuni
cittadini, contro una grande e famosa azienda informatica, e soprattutto
contro il mito dell’infallibilità dei computer nel fare i conti, che in alcuni
paesi è anche un
assunto legale:* i tribunali
danno per scontato che un computer funzioni perfettamente fino a prova
contraria.
Era più facile pensare che i singoli gestori avessero prelevato soldi dalla
contabilità della loro succursale che immaginare che il costosissimo software
contenesse errori di calcolo madornali e strutturali. Le prove informatiche
degli ammanchi sembravano talmente schiaccianti che molti consulenti legali
consigliavano ai gestori incriminati di dichiararsi colpevoli di frode
contabile; in cambio le Poste britanniche avrebbero ritirato l’accusa, ben più
grave, di furto.
[CLIP: voce di Steven Murdoch]
Steven Murdoch, professore di Security
Engineering e ricercatore presso lo University College London, ha pubblicato
un
articolo
e un video nei quali
spiega come è stato possibile questo errore informatico catastrofico, citando
esempi tratti dal disastro di Horizon e presentando alcuni concetti che
valgono per qualunque grande sistema computerizzato.
Quando un sistema informatico molto grande e distribuito sul territorio deve
gestire in modo affidabile tantissimi spostamenti di denaro e poi comunicarli
a un archivio generale, questi spostamenti non sono più semplici calcoli del
tipo
"questa succursale ha venduto sette cartoline e dodici francobolli, quindi
in cassa deve essere entrato un importo equivalente".
Gli spostamenti diventano transazioni, e queste transazioni devono
rispettare quattro criteri,
che si chiamano atomicità, coerenza, isolamento e
durabilità.
[CLIP: voce di Steven Murdoch che cita l’acronimo di questi criteri, ossia
ACID]
Atomicità significa che una transazione non può essere fatta a metà: o
viene fatta completamente, oppure no, e deve avvenire una sola volta. Ma il
software Horizon spesso creava transazioni duplicate, per cui i soldi
risultavano entrati in cassa due volte ma in realtà erano materialmente
presenti una volta sola. Alcuni gestori, non riuscendo a capire la causa degli
ammanchi in cassa, li ripianavano di tasca propria per evitare guai, ma le
grandi cifre in gioco a volte erano incolmabili. Alcuni hanno addirittura
ipotecato la casa, e l’hanno persa.
Il secondo criterio, coerenza, significa che i dati della succursale
devono essere coerenti con quelli dell’archivio centrale, ma il software
Horizon sbagliava creando contraddizioni e incoerenze che facevano sembrare
che i gestori avessero commesso delle irregolarità.
E poi c’è l’isolamento: vuol dire che se una transazione
fallisce questo non deve avere effetto su altre transazioni e che se due
transazioni avvengono contemporaneamente non devono interferire tra loro. Ma
se una transazione locale avveniva mentre veniva generato il resoconto
periodico della succursale, Horizon “dimenticava” quella transazione, creando
errori di cassa.
E infine durabilità, o persistenza, che vuol dire che una volta
che una transazione è stata avviata causando un cambiamento di stato, quel
cambiamento non deve mai andare perso in nessun caso, neanche con un
blackout o un crash del computer locale. Ma Horizon,
specialmente quando era sovraccarico, perdeva dati. Per esempio, un cliente
veniva autorizzato dal software a prelevare denaro ma poi il prelievo
effettuato non veniva registrato. E così in cassa mancavano senza
giustificazione i soldi dati al cliente.
In altre parole, realizzare un sistema contabile distribuito con decine di
migliaia di succursali non è semplice, ma gli errori che venivano commessi da
Horizon erano davvero elementari. Nonostante questo, i tribunali e le Poste
britanniche hanno preferito pensare a lungo che si trattasse di un problema di
gestori disonesti. Eppure c’era un dato concreto che avrebbe dovuto
insospettire i responsabili del software: subito dopo la sua installazione, il
numero delle anomalie di cassa era aumentato enormemente. Era improbabile che
così tanti gestori fossero diventati di colpo ladri tutti insieme, ma si è
preferito dare la colpa a lungo a loro invece che sospettare un errore del
computer e del software di Fujitsu.
I log fanno fede, ma non troppo
Il problema di queste situazioni, infatti, è che per il singolo gestore, o per
il singolo utente, risulta incredibilmente difficile dimostrare che il
software sbaglia: fanno fede infatti i cosiddetti log, ossia i registri
delle attività generati dal software stesso.
Gli
atti
dei vari
processi
per la vicenda Horizon documentano casi come quello della signora Burke,
un’addetta di una succursale postale, che si è accorta un giorno che il
prelievo di denaro fatto da un cliente, di cui lei si ricordava, non risultava
nei log. La signora è riuscita a rintracciare il cliente, è andata a casa sua
e gli ha spiegato l’accaduto. Il cliente per fortuna aveva ancora la ricevuta
rilasciatagli dal software al momento del prelievo. Quel prelievo che secondo
il software non era mai avvenuto. Se non ci fosse stata quella ricevuta
cartacea, i log avrebbero inchiodato la signora, accusandola di aver rubato
dalla cassa i soldi prelevati dal cliente.
A dicembre 2019, dopo una lunga serie di azioni legali civili, le Poste
britanniche hanno deciso di ammettere i propri errori e di indennizzare ben
555 persone per un totale di 58 milioni di sterline (circa 66 milioni di
franchi o euro). Ma i tre quarti di questa cifra non finiranno nei conti delle
vittime: serviranno a pagare le loro spese legali. E Fujitsu, intanto,
continua a essere fornitore delle Poste britanniche [e anche del governo britannico, addirittura per un servizio d’emergenza].
[Se volete approfondire questa vicenda, la BBC ha una
serie di podcast
che la raccontano in dettaglio e e moltissimi articoli con testimonianze; qui sotto c’è anche un servizio del Times]
Sarà stata imparata la lezione? Speriamo di sì. Ma nel frattempo stiamo
andando sempre più verso sistemi paperless, senza carta, senza
scontrini fisici e senza bollette stampate. Viene da chiedersi come finirebbe,
oggi, la signora Burke che si è scagionata grazie allo scontrino
provvidenzialmente tenuto dal cliente.
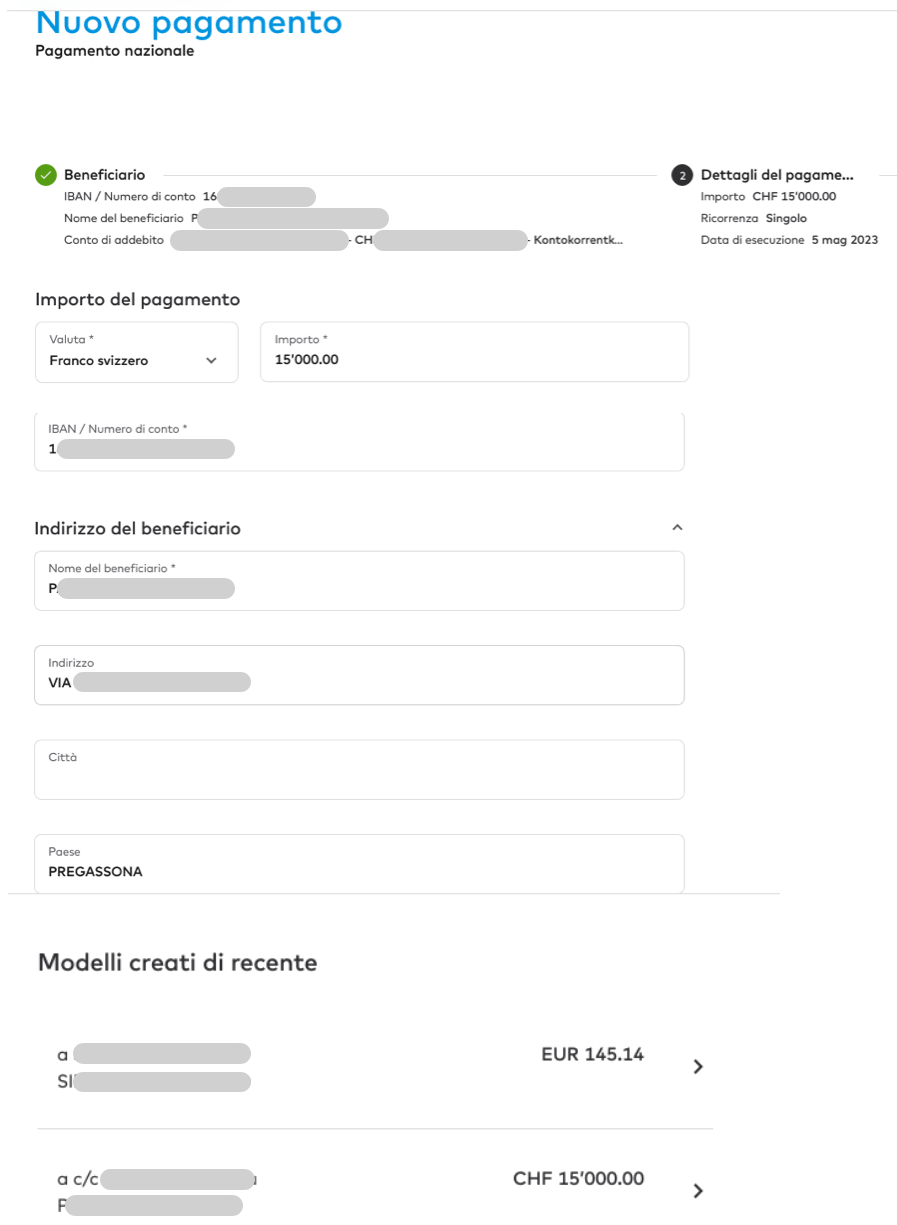
E mentre chiudo questo podcast ho davanti a me, sullo schermo, uno
screenshot della mia banca, che mi dice che sul mio conto c’è un
bonifico uscente di circa 15.000 euro* che avevo ordinato
diciassette anni fa**,
e che all’epoca era stato eseguito ma che adesso, dopo un cambio del
software gestionale della banca, è magicamente ricomparso e ogni giorno,
altrettanto magicamente, viene rimandato di un giorno senza che io faccia
nulla.
* Il bonifico è espresso in franchi; qui parlo di “circa 15.000 euro” per facilità di comprensione dell’importo da parte del pubblico non svizzero.
** Me lo ricordo perché non faccio molti bonifici di questa entità e
soprattutto ricordo il destinatario.
Screenshot composito del bonifico fantasma.
Ho ovviamente già allertato la banca, ma nel frattempo quella transazione
fantasma è ancora lì che aleggia. Sto provando a esorcizzarla recitando
ripetutamente i mantra atomicità, coerenza, isolamento, durabilità.
Speriamo che basti.
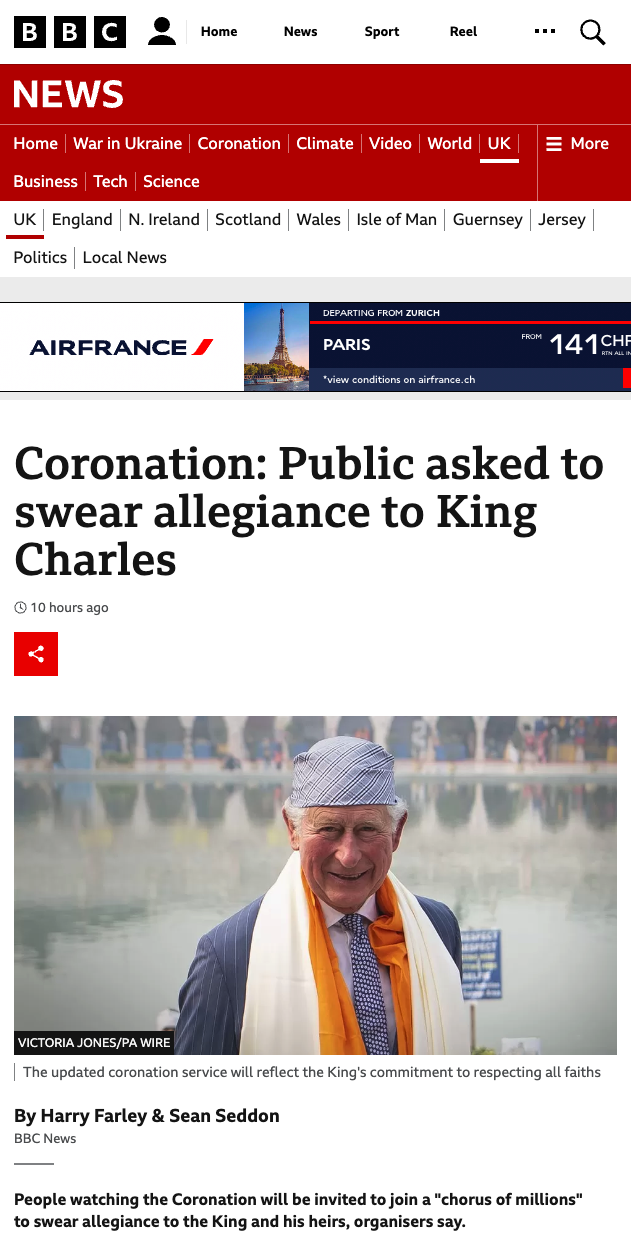
La BBC oggi titola
“Coronation: Public asked to swear allegiance to King Charles”, riferendosi all’invito ai sudditi britannici di giurare fedeltà al nuovo
monarca per creare (cito) “un coro di milioni di persone”. Questa è una novità
della cerimonia d’incoronazione. La formula da recitare sarebbe
“I swear that I will pay true allegiance to Your Majesty, and to your heirs
and successors according to law. So help me God.”
Sono (anche) cittadino britannico, ma non ho intenzione di giurare fedeltà a
un rappresentante non eletto di una monarchia. Si tratta di un invito a
giurare, e ho tutte le intenzioni di ignorarlo educatamente.
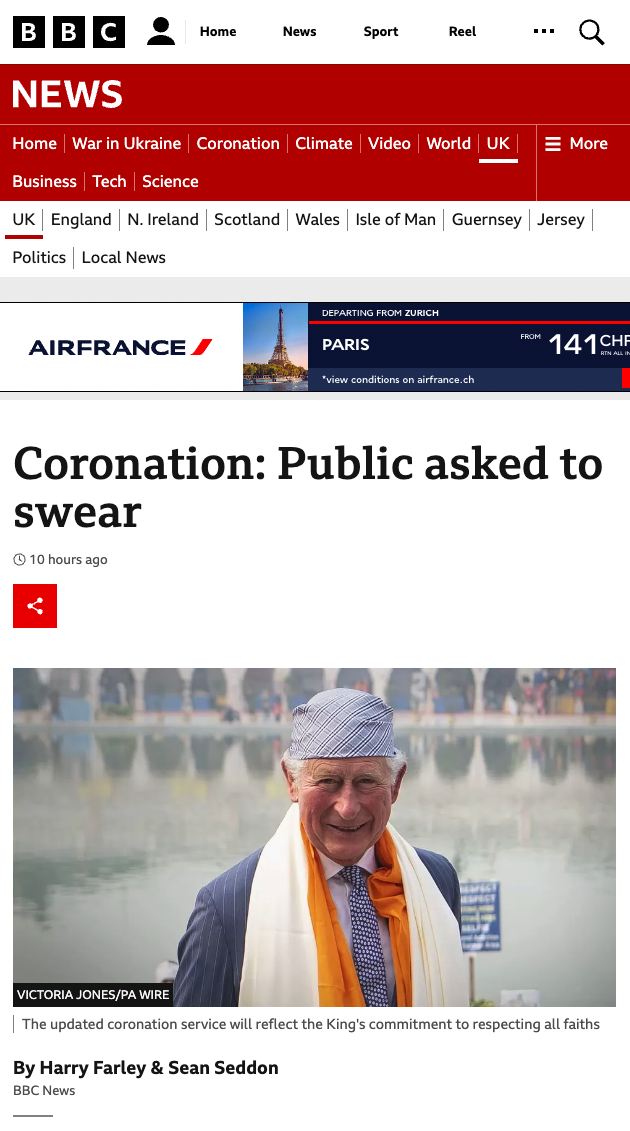
Però leggendo il titolo della BBC mi è venuto in mente quanto l’inglese sia
ambiguo e dipendente dal contesto. Il verbo to swear, infatti,
da solo significa sia “giurare” sia “dire parolacce”. È il contesto a
far capire quale delle due accezioni è quella giusta.
“To swear on the Bible” significa quindi
“giurare sulla Bibbia” e non “dire parolacce sulla Bibbia”.
E questo comporta che il titolo della BBC si presta (presumo
involontariamente) a più di una modalità di partecipazione alla cerimonia,
come illustrato qui sotto:
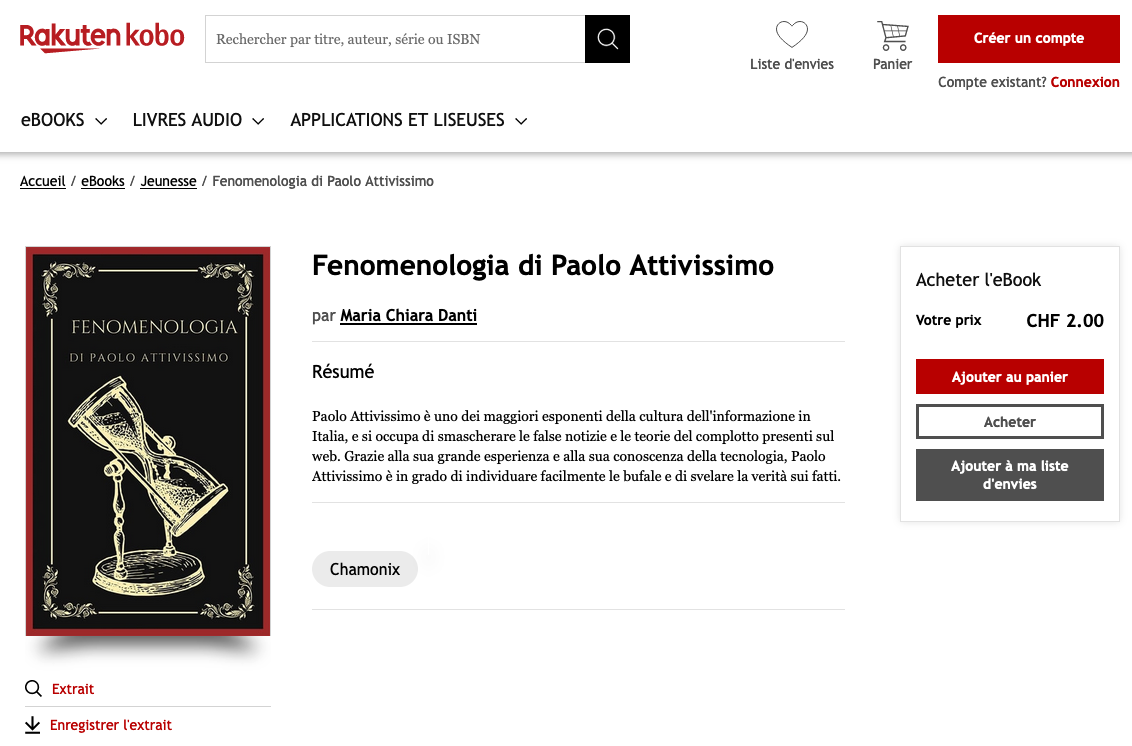
Non so chi sia Maria Chiara Danti e non so cosa l’abbia spinta a scrivere un
e-book su di me, né so cosa abbia scritto di me. So solo che stando a Kobo è
autrice straordinariamente eclettica di una ventina di libri che spaziano da
Dieta ketogenica per principianti a
Intelligenza artificiale: una guida completa ai competitor di OpenAI Chat
GPT-3
e da Il ruolo del peccato nella Bibbia: dalla Genesi all'Apocalisse a
L'Universo brillante di Margherita Hack, passando per
I segreti dell’orgasmo maschile: guida completa alle tecniche di
masturbazione.
Mi viene il dubbio che si tratti di libri generati con ChatGPT e simili, e
questo (insieme alla tediosissima necessità di creare l’ennesimo account per
acquistare qualcosa) mi trattiene dallo sborsare due euro per il suo tomo su
di me e scoprire che cosa ha scritto. Non sto chiedendo a nessuno di compiere
questo sacrificio: mi limito a segnalare con divertimento la curiosa scelta di
includere il sottoscritto fra gli argomenti (keyword?) e a chiarire
pubblicamente che non c’entro nulla con questo e-book e non sono stato
interpellato per la sua scrittura.
Accostamenti algoritmici.
18:50. Dai commenti mi arriva la segnalazione (grazie Angelo) che c’era
qui una commentatrice di nome "Maria Chiara Danti", che dopo una sparata
particolarmente polemica era stata accompagnata prontamente alla porta. Sarà
un caso?
---
2023/04/30 9:40. Ho avuto modo di leggere il “libro”: è un PDF di
quattordici pagine, con pochissimo testo per pagina, e una serie
di fandonie su di me. Secondo Maria Chiara Danti, sarei
“Nato nel 1966 a Torino” (due errori in quattro parole), avrei fatto
“studi universitari” (lo sanno anche i muri che ho iniziato a lavorare
mentre finivo il liceo), e tra le mie
“opere più famose si possono citare "Le basi della crittografia" e "Il
grande libro dello storytelling digitale"” (non ho mai scritto niente del genere). In pratica, è un ottimo esempio
di spam letterario, venduto disinvoltamente e senza alcun controllo da quasi
tutte le principali piattaforme di vendita di e-book.
Questo è l’aspetto visivo del contenuto del “libro”:
---
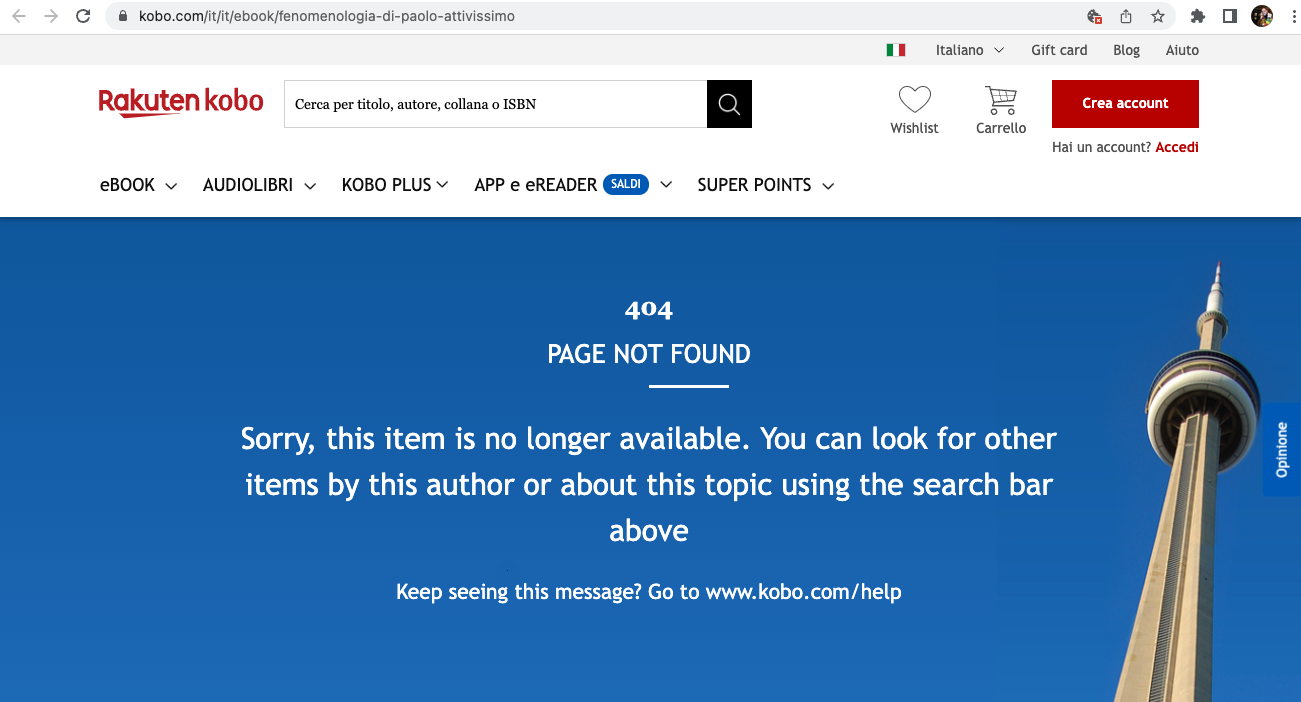
2023/05/07. Dai commenti mi arriva la segnalazione che il libro è scomparso da Kobo. Il suo link ora mostra questo:
Il “libro” risulta scomparso anche da altre piattaforme.