È disponibile subito il podcast di oggi de Il Disinformatico della Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto: lo trovate presso www.rsi.ch/ildisinformatico (link diretto) e qui sotto.
Le puntate del Disinformatico sono ascoltabili anche tramite feed RSS, iTunes, Google Podcasts e Spotify.
Buon ascolto, e se vi interessano il testo di accompagnamento e i link alle fonti di questa puntata, sono qui sotto.
---
[CLIP: Deepfake di Elon Musk che promuove servizio di criptovalute]
La voce è quella, molto caratteristica, di Elon Musk, e il video mostra chiaramente Musk che parla davanti a un microfono, in un’ambientazione da podcast, e raccomanda un sito che nasconde una truffa. Dice che un suo amico ha avuto un’idea geniale per un servizio di scambio di criptovalute che offre le condizioni migliori e la possibilità di ottenere queste criptovalute gratis. Elon Musk cita il nome del sito e invita a visitarlo.
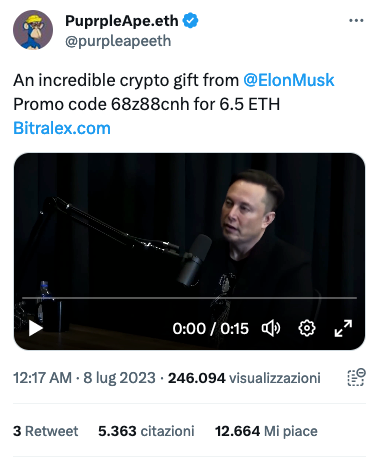
Ma è tutto finto: è l’ennesimo deepfake, pubblicato oltretutto su Twitter, che è di proprietà proprio di Elon Musk, da un utente con il bollino blu, uno di quelli che Twitter continua a definire “verificati” quando in realtà hanno semplicemente pagato otto dollari.
[Il testo era “An incredible crypto gift from @ElonMusk
Promo code 68z88cnh for 6.5 ETH hxxps://t.co/7su64bT4Dq pic.twitter.com/NjiJlcVUE2 — PuprpleApe.eth (@purpleapeeth) July 7, 2023]. Ho alterato intenzionalmente i link mettendo “hxxps” al posto di “https”]
Quel tentativo di truffa è rimasto online per almeno 24 ore, nonostante le ripetute segnalazioni degli utenti esperti, ed è stato visto da quasi 250.000 persone. Dodicimila utenti hanno anche cliccato su “mi piace”. Non c’è modo di sapere quante persone abbiano invece creduto al video e all’apparente sostegno di Elon Musk e abbiano quindi affidato i propri soldi ai truffatori.
And here's the deepfake video. pic.twitter.com/psDPV7SZz4
— @mikko (@mikko) July 10, 2023
[Segnalo la scheda informativa “Deepfake - come proteggersi” del Garante per la protezione dei dati italiano]
Sono numeri che dimostrano chiaramente il potere di inganno dei deepfake generati usando l’intelligenza artificiale per far dire in video qualunque cosa a persone molto note e usarle come involontari testimonial che promovono truffe [un altro caso di deepfake truffaldino è qui]. Ma questa è la stessa tecnologia che consente a Harrison Ford di apparire realisticamente ringiovanito di quarant’anni nel film più recente della saga di Indiana Jones.
[Clip: Fanfara di Indiana Jones, dalla colonna sonora di Indiana Jones e il Quadrante del Destino]
Due settimane fa, nella puntata del 30 giugno, vi ho raccontato alcune storie di disastri e orrori resi possibili dall’uso e abuso dell’intelligenza artificiale e ho promesso che avrei presentato anche i lati positivi, e le nuove opportunità di lavoro, di questa tecnologia tanto discussa.
Benvenuti dunque alla puntata del 14 luglio 2023 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica. Io sono Paolo Attivissimo.
[SIGLA di apertura]
Parole, parole, parole
Come tante altre tecnologie, anche l’intelligenza artificiale si presta a usi positivi e a usi negativi: dipende con che criterio la si adopera. L’esperto di intelligenza artificiale Stuart Russell, intervenuto pochi giorni fa al vertice “AI for Good” delle Nazioni Unite tenutosi a Ginevra, riassume questo criterio in un’intervista a Swissinfo con queste parole:
[CLIP: voce inglese, coperta da voce italiana che dice “Il modello di business non è 'posso risparmiare licenziando tutto il mio personale?' Il modello di business è che ora possiamo fare cose che prima non potevamo fare”]
Ne avete appena ascoltato un esempio concreto: con i metodi tradizionali e i tempi di produzione di un podcast come questo, scomodare uno speaker solo per fargli leggere in italiano le poche parole del professor Russell sarebbe stato un problema organizzativo e logistico ingestibile. Con l’intelligenza artificiale, invece, la voce può essere generata direttamente da me in una manciata di minuti usando un software come Speechify. Non è lavoro tolto a uno speaker professionista: è lavoro che uno speaker non avrebbe potuto fare e che permette di fare appunto una cosa che prima non si poteva fare: il cambio di voce permette di indicare chiaramente che si tratta di una citazione [le alternative sono cercare di far capire quando inizia e finisce la citazione usando il tono della voce, cosa che mi riesce malissimo, oppure ricorrere a formule poco eleganti come dire “inizio citazione” e “fine citazione”].
Fra l’altro, anche la voce inglese in sottofondo è generata [sempre con Speechify], eppure ha una cadenza molto naturale. Se non vi avessi detto che non è quella del professor Russell, avreste notato che era sintetica? Probabilmente no, e questo crea obblighi etici di trasparenza per chi usa queste voci giornalisticamente. Nulla di nuovo, in realtà, visto che da sempre nel giornalismo si usa far ridire da uno speaker le parole dette da una persona di cui si vuole proteggere l’identità, e si avvisa il pubblico di questo fatto. Tutto qui.
Un altro esempio di cosa che prima non si poteva fare arriva da Chequeado, che è un’organizzazione senza scopo di lucro che si impegna a contrastare la disinformazione nel mondo ispanofono. Ha creato un software di intelligenza artificiale che legge automaticamente quello che viene pubblicato nei social network, trova le notizie vere o false che si stanno diffondendo maggiormente e allerta i fact-checker, i verificatori umani, affinché possano controllarle. Questo permette alla redazione di Chequeado di concentrarsi sul lavoro di verifica e quindi di essere più efficiente e tempestiva nelle smentite delle notizie false. È un bell’esempio positivo, che si contrappone alle notizie di testate giornalistiche [CNET Money] che pubblicano articoli generati dall’intelligenza artificiale senza dirlo apertamente ai propri lettori e licenziano i redattori.
L’intelligenza artificiale offre anche un altro tipo di supporto positivo al giornalismo e a molti altri settori della comunicazione: la trascrizione automatica del parlato. Se frequentate YouTube, per esempio, avrete notato i sottotitoli generati automaticamente, a volte con risultati involontariamente comici. Ma ci sono software specialistici, come per esempio Whisper di OpenAI (la stessa azienda che ha creato ChatGPT), che sono in grado di trascrivere quasi perfettamente il parlato, e di farlo in moltissime lingue, con tanto di punteggiatura corretta e riconoscimento dei nomi propri e del contesto.
Invece di spendere ore a trascrivere manualmente un’intervista, chi fa giornalismo può affidare la prima stesura della trascrizione all’intelligenza artificiale e poi limitarsi a sistemarne i pochi errori [l’ho fatto proprio ieri per sbobinare un’intervista di ben 35 minuti di parlato che spero di poter pubblicare presto]. Gli atti dei convegni, che prima richiedevano mesi o spesso non esistevano affatto perché erano un costo insostenibile, ora sono molto più fattibili. Milioni di ore di interviste e di parlato di programmi radiofonici e televisivi storici oggi sono recuperabili dall’oblio, e una volta che ne esiste una trascrizione diventano consultabili tramite ricerca di testo, e diventano accessibili anche a chi ha difficoltà di udito, tanto che a New York un’emittente pubblica, WNYC, ha creato un prototipo di radio per i sordi, in cui le dirette radiofoniche vengono trascritte in tempo reale dal software addestrato appositamente. Tutte “cose che prima non si potevano fare”, per citare di nuovo il criterio del professor Russell, o che si potevano fare solo con costi spesso insostenibili.
E poi c’è tutto il mondo della traduzione e della programmazione. Software di intelligenza artificiale specializzati, come Trados o DeepL o Github Copilot, non sostituiscono la persona competente che traduce o scrive codice, ma la assistono nella parte tediosa e meccanica del lavoro, per esempio proponendo frasi o funzioni già incontrate in passato o segnalando potenziali errori di sintassi, grammatica e coerenza. Ma la decisione e il controllo finale devono restare saldamente nelle mani della persona esperta, altrimenti l’errore di programmazione imbarazzante sarà inevitabile e la città di Brindisi rischierà di diventare Toast, come è successo sul sito della recente campagna Open to Meraviglia del Ministero del Turismo italiano.
Produttività e accessibilità
Google ha presentato pochi giorni fa uno studio sull’impatto economico dell’intelligenza artificiale nel mondo del lavoro. È dedicato al Regno Unito, ma contiene alcuni princìpi applicabili a qualunque economia di dimensioni analoghe.
-
Il primo principio è che l’uso dell’intelligenza artificiale può far risparmiare oltre 100 ore di lavoro ogni anno al lavoratore medio, e questo costituirebbe il maggior aumento di produttività da quando fu introdotta la ricerca in Google.
-
Il secondo principio è che l’intelligenza artificiale può far risparmiare a medici e docenti oltre 700.000 ore l’anno di tedioso lavoro amministrativo in un’economia come quella britannica. Anche cose a prima vista banali, come la composizione di una dettagliata mail di richiesta di rimborso, portano via tempo e risorse mentali, se bisogna farle tante volte al giorno, e strumenti come Workspace Labs di Google permettono di offrire assistenza in questi compiti.
-
Il terzo principio, forse il più significativo, è che questa tecnologia, se usata in forma assistiva, permetterebbe a oltre un milione di persone con disabilità di lavorare, di riconquistare la propria indipendenza e di restare connesse al mondo che le circonda.
L’intelligenza artificiale consente anche di analizzare ed elaborare enormi quantità di dati riguardanti la protezione dell’ambiente, che sarebbero altrimenti impossibili da acquisire e gestire. L’azienda britannica Greyparrot, per esempio, usa l’intelligenza artificiale per riconoscere in tempo reale i tipi di rifiuti conferiti in una cinquantina di siti di riciclaggio sparsi in tutta Europa, tracciando circa 32 miliardi di oggetti e usando questi dati per permettere alle pubbliche amministrazioni di sapere quali rifiuti sono più problematici e consentire alle aziende di migliorare l’impatto ambientale delle proprie confezioni.
Passando a esempi più frivoli ma comunque utili a modo loro, l’intelligenza artificiale è uno strumento potente, e anche divertente, contro la piaga delle telefonate indesiderate di telemarketing e dei truffatori. La Jolly Roger Telephone Company è una piccola ditta californiana che permette ai suoi utenti di rispondere automaticamente a queste chiamate con voci sintetiche, pilotate da ChatGPT [CLIP in sottofondo: chiamata fra truffatore che crede di parlare con una persona anziana con difficoltà di attenzione e paranoia e per un quarto d’ora cerca di farsi dare i dati della sua carta di credito]. Tengono impegnati i televenditori e gli imbroglioni con conversazioni molto realistiche e basate sul contesto, rispondendo a tono ma senza mai dare informazioni personali.
Per un paio di dollari al mese, argomenta il creatore del servizio, Roger Anderson, si può impedire a questi scocciatori di importunare altre persone e colpire nel portafogli i criminali che tentano truffe e le aziende che fanno telemarketing spietato, e come bonus si ottengono registrazioni esilaranti delle chiamate, che rivelano chiaramente che spesso chi chiama crede di parlare con una persona vulnerabile e la tratta come un pollo da spennare senza pietà. Lo so, prima o poi anche chi fa truffe e vendite telefoniche si armerà di queste voci sintetiche, e a quel punto il cerchio si chiuderà.
Google, invece, ha presentato la funzione Try On, che permette a una persona di provare virtualmente un capo di vestiario visto online: parte da una singola immagine del capo e la manipola con un modello basato sull’intelligenza artificiale per applicarla a un corpo virtuale simile a quello dell’utente, mostrando fedelmente come l’indumento cade, si piega e aderisce al corpo. In questo modo permette di ridurre i dubbi e le incertezze tipiche di quando si compra vestiario online.
L’intelligenza artificiale, insomma, è utile quando non viene usata come sostituto delle persone, ma lavora come assistente di quelle persone per potenziarle, e va adoperata in modo consapevole, senza considerarla una divinità infallibile alla quale prostrarsi, come propongono per esempio -- non si sa quanto seriamente -- gli artisti del collettivo Theta Noir o vari altri gruppi di tecnomisticismo online.
Ma misticismi salvifici a parte, c’è un problema molto concreto che mina alla base tutte queste promesse dell’intelligenza artificiale.
La spada di Damocle
Ai primi di luglio l’attrice comica e scrittrice statunitense Sarah Silverman, insieme ad altri due autori, ha avviato una class action contro OpenAI e Meta, argomentando che i loro servizi di intelligenza artificiale violano il copyright a un livello molto fondamentale, perché includono tutto il testo dei libri di questi autori e dell’attrice, e di circa 290.000 altri libri, senza aver pagato diritti e senza autorizzazione.
Questi servizi si basano sulla lettura ed elaborazione di enormi quantità di testi di vario genere. OpenAI e Meta non hanno reso pubblico l’elenco completo dei testi usati, ma gli autori hanno notato che ChatGPT è in grado di riassumere il contenuto di molti libri con notevole precisione e quindi questo vuol dire che li ha letti. Il problema è che secondo l’accusa li ha letti prendendoli da archivi piratati. In parole povere, queste aziende starebbero realizzando un prodotto da vendere usando il lavoro intellettuale altrui senza averlo pagato [BBC; Ars Technica].
La presenza di opere protette dal copyright all’interno dei software di intelligenza artificiale sembra confermata anche da un’altra osservazione piuttosto tecnica. Molto spesso si pensa che i generatori di immagini sintetiche, come DALL-E 2 o Stable Diffusion, creino immagini originali ispirandosi allo stile delle tante immagini che hanno acquisito, ma senza copiarle pari pari: nella loro acquisizione avrebbero per così dire riassunto l’essenza di ciascuna immagine, un po’ come un artista umano si ispira legittimamente a tutte le immagini che ha visto nel corso della propria vita senza necessariamente copiarle.
Ma un recente articolo scientifico intitolato Extracting Training Data from Diffusion Models, dimostra che in realtà è possibile riestrarre quasi perfettamente le immagini originali da questi software. Questo significa che se un generatore è stato addestrato usando immagini di persone, magari di tipo medico o comunque personale o privato, è possibile recuperare quelle immagini, violando la privacy e il diritto d’autore [Quintarellli.it].
I ricercatori sottolineano che il problema riguarda uno specifico tipo di generatore, quello basato sul principio chiamato diffusion, che è il più popolare ed efficace; altri tipi [i GAN, per esempio] non hanno questa caratteristica. Se il fenomeno fosse confermato, la scala della violazione del copyright da parte delle intelligenze artificiali sarebbe colossale e porrebbe un freno drastico al loro sviluppo esplosivo commerciale. Per ora, però, questo sviluppo continua, e al galoppo: Elon Musk ha appena annunciato x.AI, una nuova azienda di intelligenza artificiale il cui obiettivo leggermente ambizioso è (cito) “comprendere la vera natura dell’universo”.
La questione di dove ci sta portando questo sviluppo poggia insomma su due pilastri: uno è il modo in cui scegliamo di usare queste intelligenze artificiali, per fornire nuove opportunità creative e di lavoro o per sopprimerle; e l’altro è il modo in cui vengono generate queste intelligenze, usando dati pubblicamente disponibili e non privati oppure attingendo ad archivi di provenienza illegittima stracolmi di informazioni sensibili. Forse, prima di tentare di comprendere la vera natura dell’universo, dovremmo concentrarci su questi concetti più semplici.