È stato pubblicato pochi giorni fa un nuovo podcast
nel quale il popolarissimo podcaster statunitense Joe
Rogan intervista un ospite molto speciale: Steve Jobs. I due si
parlano e si scambiano opinioni e battute sull’attualità per una
ventina di minuti, eppure Jobs, cofondatore di Apple, è morto nel
2011.
Medium e spiritisti non c’entrano: la voce del defunto e quella
di Joe Rogan sono state ricreate usando un generatore di voci umane
basato sull’intelligenza artificiale, disponibile presso Play.ht,
e questo non è realmente il podcast di Joe Rogan: se ci avete fatto
caso, infatti, il conduttore si è presentato come Bro Jogan,
presumibilmente per evitare complicazioni legali. Si tratta insomma
di un podcast sintetico dimostrativo, creato appunto da Play.ht.
Il generatore ha usato registrazioni pubbliche della voce di Jobs
e ha “imparato”, per così dire, a parlare come parlava lui. Il
risultato è davvero notevole: la voce è quella caratteristica che
abbiamo sentito per anni nelle presentazioni dei prodotti Apple.
L’unico indizio di artificialità è il tono, che sembra un po’
troppo da palcoscenico e leggermente fuori luogo per una
conversazione personale come è un podcast, ma questo è
probabilmente un effetto dei campioni utilizzati, che provengono
appunto dalle presentazioni fatte in pubblico. La voce di Joe Rogan,
invece, è praticamente perfetta, probabilmente perché il software
ha potuto attingere a tutti i suoi podcast, che hanno il tono giusto.
Play.ht propone un servizio nel quale i clienti usano voci
sintetiche generiche oppure personalizzate. In sostanza, è possibile
mandare all’azienda dei campioni di una voce che si desidera usare
e poi farle dire qualunque cosa. Le demo sono davvero notevoli, con
esempi delle voci sintetiche di Elon Musk, Tom Hanks e persino del
presidente statunitense John Kennedy, assassinato nel 1963.
Per ora questa tecnologia viene usata presso Podcast.ai
dichiarando esplicitamente che si tratta di voci sintetiche create
per intrattenimento e offrendo agli ascoltatori la possibilità di
scegliere gli
ospiti virtuali; inoltre i tempi di generazione sono relativamente
lenti, per cui non è possibile usare software di questo tipo per
imitare qualcuno in diretta al telefono, per esempio. Ma è il caso
di cominciare a non fidarsi delle registrazioni audio di persone
famose o dei nostri amici e conoscenti, specialmente se dicono cose
che non direbbero mai.
Pochi giorni fa ho partecipato al podcast scientifico Supernova di Border Radio, condotto da Giovanna Ranotto e Daniele Interdonato, con una chiacchierata a ruota libera su fake news e complottismi ma non solo.
Nella puntata ho raccontato anche la teoria secondo la quale la disastrosa situazione di esaltazione dell’ignoranza in cui ci troviamo sarebbe in realtà tutta colpa di Mike Bongiorno: se vi incuriosisce sapere perché, trovate la puntata su Spotify, Spreaker e Mixcloud. Buon ascolto!
Allerta spoiler: questo articolo rivela alcuni avvenimenti importanti delle
serie TV The Mandalorian e di The Book of Boba Fett.
Se state seguendo le serie TV The Mandalorian e
The Book of Boba Fett, conoscerete già una delle loro sorprese più
emozionanti: torna un personaggio amatissimo da tutti i fan di Star Wars,
e torna ringiovanito, grazie alla tecnologia digitale, con risultati
incredibilmente realistici. Non vi preoccupate: non dirò di chi si tratta. Non
subito, perlomeno [non è Yoda come l’immagine qui accanto potrebbe far pensare].
Ma a differenza di altri attori e attrici del passato, che sono stati ricreati
o ringiovaniti creando un modello digitale tridimensionale dei loro volti e
poi allineando faticosamente questo modello alle fattezze attuali dell’attore o di una sua
controfigura, con risultati spesso discutibili e innaturali, sembra (ma non è
ancora confermato ufficialmente) che in questo caso sia stata usata la tecnica
del
deepfake.
In pratica, nei deepfake si attinge alle foto e alle riprese video e
cinematografiche che mostrano quella persona quando era giovane, si estraggono
le singole immagini del suo volto da tutto questo materiale e poi si dà questo
repertorio di immagini in pasto a un software di intelligenza artificiale, che
le mette a confronto con le riprese nuove dell’attore o della controfigura e
sovrappone al volto attuale l’immagine di repertorio, correggendo ombre e
illuminazione secondo necessità. Sto semplificando, perché il procedimento in
realtà è molto complesso e sofisticato, e servono tecnici esperti per
applicarlo bene, ma il principio di fondo è questo.
Sia come sia, il risultato in The Book of Boba Fett, in una puntata
uscita pochi giorni fa, lascia a bocca aperta: le fattezze del volto ricreato
sono perfette, le espressioni pure, e il personaggio rimane sullo schermo per
molto tempo, in piena luce, interagendo in maniera naturale con gli altri
attori, mentre in passato era apparso in versione ringiovanita solo per pochi
secondi e in penombra, in disparte.
Mentre la prima apparizione di questo
personaggio digitale in The Mandalorian nel 2021 aveva suscitato
parecchie critiche per la sua qualità mediocre, nella puntata di
Boba Fett uscita di recente l’illusione è talmente credibile che fa
passare in secondo piano un dettaglio importante:
anche la voce del personaggio è sintetica.
Può sembrare strano, visto che la persona che lo interpreta è ancora in vita e
recita tuttora (non vi dico chi è, ma l’avete probabilmente già indovinato). Invece di chiamarla a dire le battute e poi elaborare
digitalmente la sua voce per darle caratteristiche giovanili, i tecnici degli
effetti speciali hanno preferito creare un deepfake sonoro.
Lo ammette candidamente Matthew Wood, responsabile del montaggio audio di
The Mandalorian, in una puntata di Disney Gallerydedicata al
dietro le quinte di questa serie: delle registrazioni giovanili dell’attore
sono state date in pasto a una rete neurale, che le ha scomposte e ha
“imparato” a recitare con la voce che aveva l’attore quando era giovane.
La rete neurale in questione è offerta dall’azienda Respeecher,
che offre servizi di ringiovanimento digitale per il mondo del cinema,
permettendo per esempio a un attore adulto di dare la propria voce a un bambino oppure
di ricreare la voce di un attore scomparso o non disponibile.
La demo di Respeecher in cui la voce di una persona normale viene convertita
in tempo reale in quella molto caratteristica di Barack Obama è
impressionante:
In The Book of Boba Fett, il tono è corretto, le inflessioni della voce
sintetica sono azzeccate, ma la cadenza è ancora leggermente piatta e
innaturale.
Ci vuole ancora un po’ di lavoro per perfezionare questa tecnologia, ma già
ora il risultato della voce sintetica è sufficiente a ingannare molti
spettatori e a impensierire molti attori in carne e ossa, che guadagnano dando
la propria voce a personaggi di cartoni animati o recitando audiolibri.
Ovviamente per chi ha seguito la versione doppiata della serie tutto questo
lavoro di deepfake acustico è stato rimpiazzato dalla voce
assolutamente reale del
doppiatore italiano
(Dimitri Winter), ma a questo punto si profila all’orizzonte la possibilità che il
deepfake della voce possa consentire a un attore di “parlare” anche
lingue straniere e quindi permetta di fare a meno del doppiaggio. Con il
vantaggio, oltretutto, che siccome il volto dell’attore è generato digitalmente, il labiale
potrebbe sincronizzarsi perfettamente con le battute in italiano, per esempio.
C’è il rischio che queste voci manipolabili a piacimento consentano di
creare video falsi di politici o governanti che sembrano dire frasi che in
realtà non hanno detto, come ha fatto proprio Respeecher nel 2019 in un caso molto
particolare: ha creato un video, ambientato nel 1969, in cui l’allora
presidente degli Stati Uniti Richard Nixon annuncia in televisione la tragica morte sulla
Luna degli astronauti Neil Armstrong e Buzz Aldrin (mai avvenuta), mettendo in bocca al
presidente parole ispirate al discorso che era stato scritto nell’eventualità
che la loro missione Apollo 11 fallisse.
Respeecher non è l’unica azienda del settore. Google, per esempio, offre il servizio Custom Voice, che permette di replicare la voce di una persona qualsiasi mandandole un buon numero di campioni audio di alta qualità. Funziona molto bene: infatti non vi siete accorti che da qualche tempo a questa parte i miei podcast sono realizzati usando la mia voce sintetica, data in pasto a un file di testo apposito.
Si fa un gran parlare di automobili “smart”, sempre più connesse e
informatizzate, e poi arrivano notizie come questa che fanno capire quanta
strada (informatica) c’è ancora da fare.
A Seattle, negli Stati Uniti, centinaia di proprietari di alcuni modelli di
auto Mazda hanno perso improvvisamente l’uso del GPS e della telecamera
posteriore e si sono trovati con l’autoradio bloccata su una singola stazione
radio. La colpa, dice Mazda, è un’immagine che hanno ricevuto, e per sistemare
il problema servirà una riparazione da circa 1500 dollari.
Come è possibile che il semplice atto di ricevere un’immagine possa
danneggiare così tanto un’automobile?
Cominciamo dall’inizio. Ai primi di febbraio 2022 vari proprietari
statunitensi di auto Mazda fabbricate fra il 2014 e il 2017 hanno iniziato a
segnalare su Reddit
un problema strano: di colpo il navigatore GPS si guastava e la telecamera
posteriore diventava inservibile. Il sistema di infotainment, ossia il
computer di bordo e lo schermo che mostrava tutte le informazioni del veicolo,
continuava a riavviarsi. Spegnere e riavviare l’auto non risolveva il
guasto.
C’era anche una coincidenza molto bizzarra: tutte le auto si erano guastate in
questo modo dopo che i proprietari avevano sintonizzato la radio di bordo
sulla stessa stazione FM, KUOW.
L’emittente radio ha notato pubblicamente la coincidenza ma ha dichiarato di
non avere idea del motivo del malfunzionamento.
Over the past couple of weeks, some people who listen to KUOW in their
Mazdas say their car radio is permanently stuck on 94.9 FM. It’s only
affecting KUOW, Mazdas from 2016, and we have no idea why.
https://t.co/ffzJASFNBJ
Inizialmente la colpa è stata data alla transizione della rete cellulare dal
3G al 5G, ma questa giustificazione era tecnicamente priva di senso. Poi è
arrivata la spiegazione reale, che a prima vista non sembra granché sensata
neanche lei: il guasto, ha detto Mazda, era stato causato
dalla stazione radio.
KUOW, infatti, è una delle tante emittenti radiofoniche del mondo che insieme
all’audio trasmette un flusso digitale di dati (specificamente con il sistema
HD Radio). Questo flusso viene ricevuto e
decodificato dalle autoradio appositamente predisposte, mostrando sullo
schermo informazioni come il nome della stazione radio, il titolo del brano
trasmesso e il nome del suo interprete, o un’immagine della copertina del
brano.
Ma KUOW aveva diffuso un’immagine al cui nome mancava l’estensione standard,
per esempio
JPG, GIF (in inglese si pronuncia ghif; in italiano gif con la G di “giraffa”)
o PNG, e il computer di bordo delle Mazda, che si aspettava che tutte
le immagini ricevute avessero un nome completo e corretto, è andato in
crash, e ci è rimasto, bloccato in un loop infinito, perché non
riusciva a riconoscere e gestire un file d’immagine privo di estensione. Non è riuscito a uscire dal loop perché quando si riavviava, la prima cosa che faceva era tentare di identificare l’immagine,
ma falliva e quindi andava di nuovo in crash. Non è un comportamento molto
smart.
Mazda ha
confermato
questa spiegazione, dicendo che la Connectivity Master Unit delle auto
colpite da questo problema non è riparabile e dovrà essere sostituita. Questo
componente costa 1500 dollari e verrà sostituito gratuitamente, ma al momento
è introvabile a causa di ritardi logistici.
Between 1/24-1/31, a radio station in the Seattle area sent image
files with no extension (e.g., missing .jpeg or .gif), which caused an
issue on some 2014-2017 Mazda vehicles with older software,” Tamara
Mlynarczyk, a public affairs manager at Mazda North American Operations,
wrote to Gizmodo. “Mazda North American Operations (MNAO) has
distributed service alerts advising dealers of the issue.
In sintesi, ancora nel 2017, quindi solo cinque anni fa, una casa
automobilistica metteva sul mercato un computer di bordo che poteva essere
danneggiato permanentemente, in modo fisico, mandandogli semplicemente
un’immagine con un nome leggermente diverso da quello che si aspettava. Il software di quel computer era
scritto così male da non saper riconoscere un’immagine se l’immagine non si
presentava
esattamente con il nome giusto.
E non è neanche la prima volta che succede. Nel 2019 alcune Mazda erano
impazzite quando i loro proprietari avevano cercato di ascoltare uno specifico
podcast. La colpa, ancora una volta, era del software, che non sapeva gestire
una cosa banale come un carattere non alfabetico nel nome del podcast. Il
podcast, infatti, si intitolava
99% Invisible, con il numero scritto in cifre e accompagnato dal simbolo di percentuale.
Quel simbolo veniva interpretato male, causando un crash.
Va sottolineato che questo incidente con la stazione radio KUOW non riguarda
delle auto connesse a Internet: il “malware”, se vogliamo chiamarlo così,
ossia l’immagine involontariamente ostile, viene ricevuto via radio. Oggi molti
utenti, soprattutto informatici, sono preoccupati per la nuova tendenza a
collegare le auto a Internet e credono che quelle non connesse siano più
sicure. Ma questo episodio dimostra che non è necessariamente così.
Il problema di fondo, qui, non è la connessione a Internet o meno: è il modo
in cui viene scritto il software che oggi gestisce praticamente qualunque
automobile. Se non è scritto bene, rispettando regole elementari come
“non fidarti ciecamente di quello che ti arriva” (la cosiddetta
input sanitization) e isolando bene le funzioni di intrattenimento da quelle necessarie per la
guida, come il GPS o la telecamera di retromarcia, incidenti come questo
continueranno a succedere.
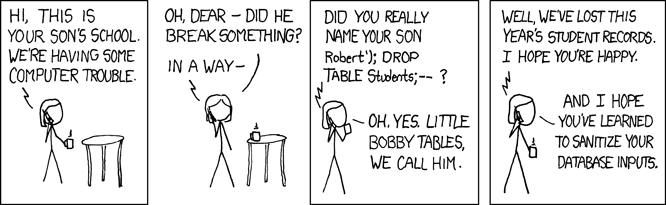
Quasi quasi come titolo della prossima puntata del podcast scelgo
apice UNION SELECT username, password FROM userstrattino trattino. E vediamo che succede :-)
È disponibile subito il podcast di oggi de Il Disinformatico della
Radiotelevisione Svizzera, scritto e condotto dal sottoscritto: lo trovate
presso
www.rsi.ch/ildisinformatico
(link diretto) e qui sotto.
Buon ascolto, e se vi interessano il testo e i link alle fonti della storia di
oggi, sono qui sotto!
---
[CLIP: digitazioni su tastiera]
Ormai è quasi impossibile girare su Internet senza imbattersi nella tediosa
richiesta di cliccare su una casellina per confermare di non essere un robot o
in quella di cliccare su delle immagini che mostrano autobus o semafori.
Perché è necessaria questa dichiarazione, e come mai così tanti siti sono così
tanto interessati agli autobus e invece discriminano le eventuali forme di
vita artificiali che sono online?
Questa è la storia dei captcha: uno dei tormenti moderni ma non troppo
di Internet.
[SIGLA]
Nella preistoria di Internet, negli anni Novanta del secolo scorso per
intenderci, quando Google non esisteva ancora (sì, è esistita un’epoca in cui
Google non c’era), il motore di ricerca più popolare era un altro:
AltaVista (ve lo
ricordate?).
Beh, in quell’epoca c’erano già gli spammer. Quelle simpatiche creature
subumane che appestano qualunque cosa digitale riempiendola di pubblicità dei
loro siti che vendono prodotti discutibili per risolvere problemi intimi
ancora più discutibili.
A quell’epoca gli spammer prendevano appunto di mira AltaVista, che usava un
metodo molto primitivo per catalogare Internet: erano gli utenti a compilarlo
mandandogli le informazioni sui siti che ritenevano interessanti. E così gli
spammer usavano programmi automatici per inondare AltaVista di segnalazioni
dei propri siti pieni di cure miracolose. I tecnici di AltaVista le
cancellavano sistematicamente, ma gli spammer ne mandavano altre, e quindi il
problema non si risolveva.
Così AltaVista decise di introdurre un test che potesse essere superato
soltanto da un essere umano. Questo avrebbe impedito ai programmi automatici
degli spammer di funzionare.
Il test consisteva nel mostrare sullo schermo di chi voleva inviare dati ad
AltaVista delle
lettere molto deformate, che un umano di solito riusciva a riconoscere senza problemi ma che erano
completamente incomprensibili per un programma automatico. Ovviamente questo
causava problemi agli utenti onesti ipovedenti o ciechi, ma non c’era molta
scelta.
La soluzione sembrava semplice ed elegante e le fu presto però associato un
nome molto meno elegante:
Captcha, che sta per (tenetevi forte)
Completely Automated Public Turing Test to tell Computers and Humans
Apart. Traduzione: Test di Turing completamente automatizzato per distinguere i
computer dagli umani. Turing, per chi non lo conosce, è uno dei padri
dell’informatica: da lui nasce il
Test di Turing, che
serve appunto per distinguere un essere umano da un computer che finge di
essere un essere umano.
Nel 2007 uscì una versione più sofisticata, denominata ancora peggio
Recaptcha. Cercava di incoraggiare gli utenti a collaborare, spiegando che la loro
azione contribuiva alla digitalizzazione dei libri cartacei e dei vecchi
giornali. Recaptcha, infatti, mostrava due parole deformate: una che i suoi
gestori già avevano identificato correttamente e una che invece i sistemi di
riconoscimento automatico dei caratteri non avevano ancora decifrato.
L’utente doveva scriverle entrambe: la prima doveva essere trascritta
correttamente e serviva a dimostrare che l’utente era davvero un essere umano,
mentre la seconda, quella sconosciuta, andava semplicemente tentata. Se tanti
utenti davano la stessa risposta alla stessa parola, quella risposta diventava
parte del testo digitalizzato del libro o giornale d’epoca. In altre parole,
gli utenti contribuivano, parola dopo parola, a digitalizzare tantissimi testi
cartacei.
La cosa piacque così tanto che Recaptcha fu comprato da Google e i captcha in
generale furono usati per impedire la creazione massiccia e abusiva di account
di mail usa e getta da parte dei venditori di spazzatura digitale.
Ma questi spammer non si arresero. Negli anni che erano passati da quei primi,
semplici captcha, la tecnologia del riconoscimento delle immagini aveva fatto
enormi progressi, soprattutto nel riconoscimento dei testi, per cui
cominciarono a usare computer sempre più potenti per decifrare le parole
distorte e scavalcare il filtro antispam.
Questo, però, era un metodo costoso, per cui gli spammer ne inventarono presto
un altro molto meno tecnologico: subappaltarono il riconoscimento a degli
esseri umani che vivevano in paesi a basso reddito. Migliaia di persone
venivano pagate una miseria per risolvere un captcha dopo l’altro, per ore di
fila. Nacquero addirittura aziende specializzate nella risoluzione dei
captcha. Alcune di loro esistono ancora oggi.
Però questi lavoratori, autentici schiavi digitali, andavano comunque pagati,
e in un mercato come quello dello spam, dove i margini sono bassissimi, il
costo di quella paga era un problema.
Così gli spammer hanno inventato di recente un’altra soluzione: far risolvere
i captcha agli utenti normali, senza che se ne rendano conto. Per esempio,
basta creare un sito che contiene qualcosa che gli utenti desiderano
(immagini, video, musica, film) e chiedere loro di risolvere un captcha prima
di poterlo consultare. Il captcha, in realtà, viene preso di peso
istantaneamente da un altro sito, quello nel quale gli spammer vogliono
entrare superandone il filtro.
È a questo punto che Google ha risposto con la casella che oggi tutti
conosciamo, quella che chiede di confermare che non siamo dei robot. Un solo
clic su una sola casella, e il captcha è risolto.
[CLIP: Clic di un mouse]
Sembra una cosa troppo facile, che persino un programma automatico sarebbe in
grado di fare, ma c’è il trucco. In realtà dietro le quinte questo captcha
trasmette moltissimi dati a Google, che permettono all’azienda di discriminare
fra una cliccata fatta da un programma automatico e una fatta da un essere
umano.
Quali siano questi dati non si sa. Google non vuole rivelarli per non dare
aiuti agli spammer. Forse rileva i tempi di reazione o i movimenti del mouse o
del dito; forse legge i cookie che Google deposita sui nostri dispositivi,
visto che quando si prova a risolvere uno di questi captcha durante la
navigazione privata compare puntualmente un secondo test, quello con la
griglia di immagini di autobus, gattini o barche da identificare. Immagini che
forse servono ad addestrare le future auto a guida autonoma, vista la loro
particolare predilezione per le scene stradali complesse.
Esiste anche una versione ulteriore di questo captcha, che ha debuttato alcuni
anni fa, nel 2017, ed è ancora più sofisticata: infatti è completamente
invisibile. In questo captcha, Google si limita a osservare il comportamento
dell’utente, come muove il mouse o il dito, come fa scorrere lo schermo, come
digita le informazioni, e poi usa sofisticati sistemi di intelligenza
artificiale per decidere se si tratta di un essere umano o di un sistema
automatico. Anche qui, bocche cucite: i dettagli del suo funzionamento non
sono pubblici.
La rincorsa fra guardie e ladri continua: avrete notato che oggi alcune banche
cominciano a chiedere di identificarsi apparendo in video in tempo reale,
mostrando il proprio documento d’identità oltre che il proprio volto, e questo
sembra un sistema molto difficile da eludere. Neppure i
deepfake riescono a falsificare un video in tempo reale.
Resta il problema di tutti coloro che hanno disabilità e quindi sono tagliati
fuori da questi sistemi. Non ci vuole molto: anch’io spesso vengo ingannato
dai captcha. E resta anche il problema dell’invasività sempre maggiore di
questi metodi per distinguere un umano da un robot. Per non parlare della
frustrazione e dell’umiliazione di non riuscire a superare un test che
dovrebbe, in teoria, essere alla portata di qualunque persona cosiddetta
“normale”.
Dove finirà questa rincorsa è difficile da dire. I sistemi di certificazione
dell’identità digitale, come l'EIDAS dell’Unione Europea o SwissID, sono una
possibile soluzione, ma non sono universali e spesso incontrano resistenze da
parte di chi li considera eccessivamente a rischio per la privacy, la
sorveglianza governativa e lo sfruttamento commerciale dei dati degli utenti.
E in molti paesi semplicemente non esistono o hanno costi e complicazioni che
li rendono inavvicinabili per una fetta importante della popolazione.
Nessun vuole Internet divisa in due categorie: cittadini e internauti di serie
A e di serie B. E forse dovremo tornare a chiedere di cliccare più spesso su
tanti gattini.
È disponibile subito il podcast di oggi de Il Disinformatico della Rete
Tre della Radiotelevisione Svizzera, condotto dal sottoscritto: lo trovate
presso
www.rsi.ch/ildisinformatico
(link diretto). Questa è la versione Story,
dedicata all’approfondimento di un singolo argomento.
Se vi interessano il testo e i link alle fonti della storia di
oggi, sono qui sotto. Buon ascolto!
---
[CLIP: (in sottofondo) Vento e rumori di una città deserta]
Qui una volta, neanche tanto tempo fa, viveva tanta gente. Le strade erano
piene di vita, c’erano negozi, luoghi d’incontro, milioni di cittadini,
un’economia fiorente e in crescita, un artigianato creativo e originale. Gli
esperti dicevano che questa sarebbe stata la comunità del futuro, con nuove
leggi e nuove forme di cultura e socialità.
Oggi c’è il deserto: la popolazione è crollata, nei negozi non c’è più quasi
nessuno e le ambasciate aperte con entusiasmo e milioni di dollari pochi anni
fa sono deserte.
Questa è la storia di Second Life, la comunità virtuale che molti
commentatori, in questi giorni, citano come modello e monito a proposito del
Metaverso, la nuova esperienza virtuale di Internet proposta da Mark
Zuckerberg, e di come il suo fallimento e i suoi errori possono illuminare la
strada verso il futuro immersivo descritto dal fondatore di Facebook.
---
È il 23 giugno 2003: Philip Rosedale della Linden Labs pubblica Second Life,
un’applicazione che consente agli utenti Windows, Mac e Linux di creare un
simulacro digitale di se stessi, un avatar, e di muoverlo in un mondo virtuale
tridimensionale, interagendo con altri utenti tramite la voce e i gesti, per
socializzare e partecipare ad attività di gruppo, costruire ambienti,
fabbricare oggetti virtuali, comprarli e venderli. Second Life ha una moneta,
il Linden Dollar. Non è un gioco: non c’è un obiettivo o un traguardo da
raggiungere. Second Life è un luogo, dove sono gli utenti a decidere cosa
succede e ognuno può scegliere di avere l’aspetto che preferisce.
È una rivoluzione: gli utenti arrivano a frotte e non si parla d’altro. I
giornali generalisti descrivono Second Life esaltandone le immense opportunità
economiche. Nel 2005 Linden Labs dichiara che l’economia di Second Life ha
generato tre milioni e mezzo di dollari in un solo mese. Nel 2006 il PIL di
Second Life sale a 64 milioni. In Second Life si tengono concerti e
conferenze, compreso il World Economic Forum di Davos, le imprese
acquistano spazi virtuali pagandoli fior di quattrini, i governi aprono
consolati per fornire informazioni e servizi. Nel 2007 anche il ministro
italiano delle infrastrutture, Antonio Di Pietro, apre uno spazio su Second Life per il proprio movimento politico.
Ma proprio nel 2007 cominciano ad arrivare le stroncature. Second Life risulta
lento e macchinoso da usare, la sua grafica è rudimentale e richiede computer
potenti e una connessione veloce a Internet; ma soprattutto gli oltre otto
milioni di utenti vantati da Second Life sono in realtà tutti coloro che si
sono iscritti gratuitamente, sono entrati una volta sola e non si sono più
ripresentati.
Secondo i dati di Forrester Research, anche nei momenti di punta
non ci sono mai più di 30-40.000 utenti collegati attivi. I negozi virtuali
delle aziende sono deserti. Subentra un certo imbarazzo, perché uno degli
oggetti più commerciati su Second Life è costituito dai genitali (che si
devono comperare a parte). La bolla scoppia.
Oggi Second Life esiste ancora. Dichiara circa 900.000 utenti attivi: niente,
rispetto ai tre miliardi di Facebook e alle centinaia di milioni di tanti
altri social network e mondi virtuali più recenti, come Roblox o Minecraft. I
suoi Linden Dollar, che una volta si scambiavano alla pari con il dollaro
statunitense, sono quasi carta straccia: nel 2020 il tasso di cambio era 320
Linden Dollar per un solo dollaro americano. La grafica è migliorata, i
computer odierni hanno tutti una potenza di calcolo più che sufficiente e le
connessioni Internet veloci sono ovunque.
Ma resta un problema di fondo: esattamente a che cosa serve Second Life?
[CLIP: Zuckerberg presenta il Metaverso]
Se tutto questo vi sembra molto familiare, è normale. Il Metaverso proposto a
ottobre 2021 da Mark Zuckerberg con enorme visibilità mediatica è, sotto molti
punti di vista, una riedizione delle idee di Second Life, ma con una
tecnologia decisamente superiore e un’ideologia molto chiara sin da subito,
che si riassume in due parole: soldi e dati.
A differenza di Second Life e di molti altri mondi virtuali, il Metaverso di
oggi non è limitato a qualcosa che abbiamo davanti a noi sullo schermo e che
comandiamo toccando dei tasti: può essere usato anche in questo modo, ma si
estende anche alla realtà virtuale e alla realtà aumentata. Non c’è un
“dentro” e un “fuori”, una linea netta di confine: si può entrare nel
Metaverso in maniera graduale.
Il livello più semplice è ancora basato sullo schermo tradizionale: Microsoft,
per esempio, ha annunciato che offrirà gli avatar in Teams. Potremo quindi
partecipare a una videoconferenza su Teams presentandoci con un’immagine
animata tridimensionale, che duplicherà i nostri gesti e le nostre
espressioni, al posto della nostra immagine video spettinata, struccata,
sonnolenta e male illuminata. Per chiunque abbia difficoltà o disagi nel
presentare il proprio aspetto o la propria identità, questo può essere un
miglioramento sociale notevolissimo. Questo livello non richiede occhiali
speciali, visori per realtà virtuale o altri accessori: basta una normale
telecamera.
Chi invece ha questi accessori può vivere il Metaverso in maniera molto più
immersiva. Gli occhiali per realtà aumentata promettono di mostrare oggetti o
persone virtuali integrati direttamente – perlomeno a livello visivo – nel
mondo reale. Vedere famiglia e amici lontani come se fossero seduti nel nostro
soggiorno è sicuramente allettante. E naturalmente i pubblicitari hanno già
l’acquolina in bocca al pensiero di assalire i nostri sensi con spot virtuali
animati che sbucano dai muri per convincerci a comperare nuovi prodotti e
servizi.
Con i visori per la realtà virtuale, quelli che coprono tutto il campo visivo
con immagini tridimensionali, tutto quello che vediamo intorno a noi è creato
digitalmente e quindi è manipolabile in mille modi. Possiamo presentarci con
avatar tridimensionali, andare virtualmente a eventi o concerti con la
sensazione visiva di essere in mezzo al pubblico o addirittura sul palco,
esplorare in tutta sicurezza luoghi inaccessibili, accogliere gli amici in una
casa virtuale lussuosa e sempre magicamente pulita e in ordine. Questa è la
forma più ricca del Metaverso, che però non è solo realtà virtuale: il
Metaverso è una tecnologia ben più ampia e abilitante.
Molte aziende qui fiutano l’odore dei soldi: quegli avatar andranno vestiti in
qualche modo, e quindi si potranno vendere indumenti virtuali, esattamente
come oggi si comprano a caro prezzo skin e altri accessori in giochi come
Fortnite o Call of Duty. Quei concerti e quei luoghi virtuali avranno un
biglietto d’ingresso. Quelle ville virtuali dovranno essere progettate e
costruite da qualcuno, e sarà socialmente necessario che siano personalizzate,
naturalmente a pagamento, perché sarà considerato imbarazzante presentarsi con
una casa standard, un po’ come nel libro Snow Crash di Neal Stephenson, lo
scrittore che ha coniato il termine “metaverso”, i poveri hanno accesso a
questo ambiente virtuale tramite terminali pubblici che li visualizzano in
bianco e nero, aprendoli alla derisione degli altri.
Questi comportamenti sociali, però, non sono fantascienza: già oggi in
Fortnite i giocatori deridono e bullizzano gli altri utenti che non comprano le
skin personalizzate per i propri avatar e si presentano con l’aspetto
standard, esattamente come si viene a volte sbeffeggiati e umiliati perché ci
si presenta a scuola o in ufficio con le scarpe o i vestiti dell’anno scorso.
Le imprese hanno così già la salivazione accelerata: ci saranno da vendere
tanti oggetti virtuali e anche oggetti reali per poter fruire di quelli
virtuali. Per sfoggiare la skin del proprio avatar all’ultima moda bisognerà
infatti avere un casco per realtà virtuale di nuova generazione e serviranno
connessioni mobili, probabilmente 5G, sempre più veloci.
L’interesse commerciale, però, non è solo direttamente monetario: l’uso del
Metaverso, specialmente tramite occhiali per realtà aumentata e visori per
realtà virtuale ma anche con semplici telecamere che ci riprendono, regala
alle aziende montagne di dati biometrici e fisiologici altrimenti
inaccessibili e immensamente monetizzabili.
Cose come il modo in cui ci muoviamo, in che direzione guardiamo, come
parliamo, come respiriamo, che espressioni facciamo, se abbiamo messo su
qualche chilo di troppo e dove, quanto movimento fisico facciamo: dati
estremamente personali, usabili sia per diagnosticare lo stato di salute di
miliardi di persone, con ovvie conseguenze per la privacy, sia per
personalizzare ancora di più le offerte pubblicitarie. “Abbiamo notato che
sorridi di meno ultimamente. Ti serve un antidepressivo? Vuoi vedere un film
comico? Ti interessa un sito di incontri?”
Il metaverso e gli avatar pongono anche delle nuove sfide sul fronte della
sicurezza informatica. Oggi siamo purtroppo abituati al ransomware che blocca
i dati aziendali e chiede un riscatto per sbloccarli; nel metaverso
arriveranno, inevitabilmente, anche i criminali informatici con forme di
attacco su misura per questo ambiente. Non è difficile immaginare un
ransomware che toglie i vestiti al nostro avatar e chiede soldi per non farci
andare in giro nel metaverso nudi o farci partecipare a una videoconferenza
serissima conciati come Pennywise, il pagliaccio assassino di It.
Per le imprese, insomma, anche stavolta i motivi di lucro per interessarsi al
metaverso non mancano, e questo spiega il fragore mediatico dell’annuncio di
Mark Zuckerberg. Rispetto ai tentativi passati, come Second Life, è cambiata
però un’idea fondamentale: il metaverso oggi viene proposto come un’esperienza
fluida e continua, che ingloba tutto e non ha barriere. In Second Life
bisognava entrare, e quello che si creava restava lì, sui computer di una
specifica azienda; nel metaverso prossimo venturo, invece, gli avatar, gli
oggetti e gli indumenti creati saranno esportabili e usabili ovunque, grazie a
standard aperti. O almeno così ci viene promesso: ci sono ancora parecchi
ostacoli tecnici ed economici notevoli da superare.
Nel frattempo resta senza risposta una domanda, che è la stessa che mise in
crisi Second Life: esattamente a cosa serve il Metaverso? A parte fare soldi
per le aziende, intendo.
Manca, per ora, la cosiddetta killer app del
Metaverso: quell’applicazione i cui pregi sono così evidenti e irresistibili
da spingere tanti ad acquisire gli strumenti necessari per poterla usare. In
passato abbiamo avuto killer app come VisiCalc e WordStar, un foglio di
calcolo e un programma di scrittura testi che fecero esplodere il mercato dei
personal computer, o Video Toaster sugli Amiga, o ancora Excel e poi Microsoft
Office per il mondo Windows.
È impossibile prevedere quale sarà questa killer app. Specialmente in
informatica, cercare di prevedere il futuro è come guidare a fari spenti lungo
una stradina di campagna guardando nello specchietto retrovisore. E quindi
questa è un’altra storia.
È disponibile subito il podcast di oggi de Il Disinformatico della Rete
Tre della Radiotelevisione Svizzera, condotto dal sottoscritto: lo trovate
presso
www.rsi.ch/ildisinformatico
(link diretto). Questa puntata (la numero 700 da quando ho iniziato, nel 2006) è in versione Story,
quella sperimentata quest’estate e dedicata all’approfondimento di un singolo
argomento, che sarà il format standard dal 5 novembre prossimo.
Buon ascolto, e se vi interessano il testo e i link alle fonti della storia di
oggi, sono qui sotto!
Nota: la parola CLIP nel testo che segue non è un segnaposto in
attesa che io inserisca dei contenuti. Indica semplicemente che in quel punto
del podcast c’è uno spezzone audio. Se volete sentirlo, ascoltate il podcast
oppure guardate il video (se disponibile) che ho incluso nella trascrizione.
[CLIP: (in sottofondo) Rumore di tastiera di computer degli anni 90]
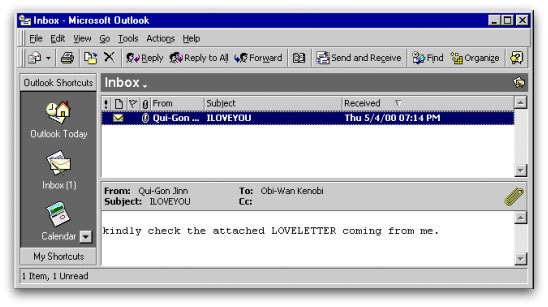
È il 4 maggio 2000, un giovedì come tanti a Manila, nelle Filippine. Uno
studente d’informatica, il ventiquattrenne Onel de Guzman, vuole collegarsi a
Internet, come tante altre persone in tutto il mondo quel giorno.
Ma Onel non sa ancora che tra poche ore scatenerà il caos informatico
planetario, causando danni per oltre dieci miliardi di dollari, travolgendo il
Pentagono, la CIA, il Parlamento britannico e moltissime aziende
multinazionali. Farà tutto questo usando un singolo computer e un messaggio
d’amore ingannevole, che si propagherà via mail in decine di milioni di
esemplari perché gli utenti non sapranno resistere alla curiosità di sapere
cosa c’è dietro le tre parole di quel semplice messaggio scritto da Onel:
I Love You.
Mentre preparo questo podcast, la
Svizzera
e
molti paesi europei
sono invasi da messaggi digitali che stuzzicano gli utenti allo stesso modo:
sono SMS che dicono che c’è un
messaggio vocale importante
per loro. Chi non resiste alla tentazione, li apre e ne segue ciecamente le
istruzioni finisce per farsi infettare lo smartphone e per farsi rubare il
contenuto del proprio conto bancario.
Questa è la storia di quell’attacco informatico mondiale di oltre vent’anni fa
e dei suoi paralleli con quello in corso attualmente. Gli anni passano, la
tecnologia cambia, ma la leva più potente per scardinare le difese
tecnologiche rimane sempre la stessa: la curiosità umana.
[SIGLA]
Torniamo a Manila e a quello studente d’informatica, Onel de Guzman. È
squattrinato e le connessioni a Internet costano. Così ha un’idea: scrivere un
worm, ossia un programma autoreplicante che rubi le password di accesso
a Internet di altri utenti, così lui potrà collegarsi senza pagare.
Per creare questo worm, de Guzman sfrutta una delle scelte più
fallimentari della storia dell’informatica: quella di nascondere
automaticamente le cosiddette estensioni dei nomi dei file. Ogni file,
infatti, ha un nome che è composto da una parte principale e da un’estensione:
se scrivete un documento con Microsoft Word e lo chiamate Fattura, il
suo nome completo sarà Fattura.docx. Docx è l’estensione. Il
punto separa la parte principale del nome dalla sua estensione.
Questa estensione viene usata spesso dai dispositivi digitali per sapere come
gestire un file: per esempio, se l’estensione è xls o xlsx,
allora si tratta di un foglio di calcolo, che va aperto con Excel; se
l’estensione è odt, è un documento di testo che va aperto con
LibreOffice o OpenOffice; se l’estensione è mp3, è un brano musicale o
un file audio, e così via.
Ma normalmente Windows nasconde le estensioni, appunto, e Onel lo sa bene.
Così crea un worm che manda una mail che contiene un allegato il cui
nome termina con .txt.vbs. In questo modo chi riceve l’allegato vede un
file che ha apparentemente l’estensione txt, che identifica i file di
testo normale, assolutamente innocui, ma in realtà il file è uno
script, ossia un programma scritto in Visual Basic.
In altre parole, l’allegato sembra un documento perfettamente sicuro agli
occhi della vittima, ma il computer della vittima lo interpreta come una serie
di comandi da eseguire.
Non solo: Onel de Guzman approfitta anche di un altro errore monumentale
presente in Microsoft Outlook a quell’epoca: Outlook esegue automaticamente
gli script in Visual Basic che riceve in allegato se l’utente vi clicca sopra.
Queste due falle, concatenate, permettono a de Guzman di confezionare un
attacco potentissimo: le vittime ricevono via mail quello che sembra essere un
documento non pericoloso ma è in realtà un programma, lo aprono per sapere di
cosa si tratta, e il loro computer esegue ciecamente quel programma. Il
programma a quel punto si legge tutta la rubrica degli indirizzi di mail della
vittima e la usa per mandare una copia di se stesso a tutti i contatti del
malcapitato utente intanto che ruba le password di accesso a Internet.
L’effetto valanga che ne consegue è rafforzato dall’ingrediente finale scelto
da Onel de Guzman: il nome dell’allegato l’oggetto della mail è I Love You,
“ti amo” o “ti voglio bene” in inglese, scritto senza spazi.
Mettetevi nei panni delle vittime di questo attacco: ricevete una mail che vi
invita a leggere una lettera d’amore. Questa lettera, oltretutto, proviene da
qualcuno che conoscete. Riuscireste a resistere alla tentazione di aprirla?
Il risultato di questa tempesta perfetta di difetti informatici e di astuzia
psicologica è un’ondata virale di messaggi che nel giro di poche ore intasa i
computer di mezzo mondo, causando confusioni e congestioni a non finire, anche
perché il virus informatico non si limita ad autoreplicarsi massicciamente, ma
rinomina e cancella anche molti dei file presenti sui dischi rigidi delle
vittime.
Vengono colpiti il settore finanziario di Hong Kong, il parlamento danese,
quello britannico, la CIA, il Pentagono, la Ford e Microsoft stessa,
paralizzate dall’enorme traffico di mail; lo stesso accade a quasi tutte le
principali basi militari degli Stati Uniti. Le infezioni segnalate nel giro di
dieci giorni sono oltre cinquanta milioni: circa il 10% del computer di tutto
il mondo connessi a Internet. I danni e i costi di ripristino ammontano a
decine di miliardi di dollari.
[CLIP: reporter di CTV che riferisce dei danni causati da Iloveyou (da 0:09
a 0:23)]
Eppure Onel de Guzman, con il suo worm Iloveyou, voleva soltanto
procurarsi qualche password per connettersi a Internet senza pagare.
[CLIP: Suono di modem che si collega in dialup]
Quando si rende conto del disastro che ha involontariamente combinato, cerca
di coprire le proprie tracce, ma è troppo tardi: nel giro di pochi giorni
viene rintracciato dalle autorità.
Ma le leggi delle Filippine nel 2000 non includono i reati informatici e
quindi de Guzman non è punibile, perché non ha commesso alcun reato.
Negli anni successivi il creatore accidentale di uno dei virus informatici più
distruttivi della storia scomparirà dalla scena pubblica. A maggio del 2020
viene rintracciato da un giornalista, Geoff White, che scopre che Onel de
Guzman lavora presso un negozietto di riparazione di telefonini a Manila. Ogni
tanto qualcuno lo riconosce, ma lui mantiene un profilo basso ed evita ogni
attenzione mediatica. Chissà se sa che nel 2002 i Pet Shop Boys hanno scritto
una canzone, E-mail, che a giudicare dal testo, con quella richiesta di
mandare una mail che dice "I love you", sembra proprio dedicata a lui.
---
Da quell’attacco informatico sferrato per povertà da uno studente oltre
vent’anni fa sono cambiate molte cose. Le Filippine, come moltissimi altri
stati, ora hanno leggi che puniscono severamente il furto di password e il
danneggiamento dei sistemi informatici. Microsoft ha chiuso le falle tecniche
che avevano permesso a Onel de Guzman e a molti altri suoi emuli di creare
programmi ostili autoreplicanti.
Ma dopo molti anni senza ondate di virus informatici diffusi automaticamente
via mail, in questi giorni è ricomparso un worm che usa esattamente le
stesse tecniche sfruttate da Onel de Guzman e si sta diffondendo a moltissimi
utenti di smartphone in un elevato numero di copie. Si chiama FluBot, e
invece di usare la mail adopera gli SMS, ma a parte questo segue il medesimo
copione.
La vittima di FluBot riceve un SMS il cui mittente è qualcuno che conosce e di
cui quindi tende a fidarsi, proprio come capitava con Iloveyou. L’SMS contiene
un invito a cliccare su un link per ascoltare un messaggio vocale, e siccome
proviene da un suo contatto scatta la molla emotiva della curiosità, oggi come
vent’anni fa.
Il messaggio vocale, però, in realtà non esiste e il link porta invece a un
avviso che dice che per ascoltare il messaggio la vittima deve installare
un’app apposita non ufficiale che non si trova nei normali archivi di app.
Questa app è il virus vero e proprio.
Se la vittima abbocca all’esca emotiva e la installa, FluBot prende il
controllo dello smartphone e si mette in attesa. Quando la vittima usa il
telefonino per una transazione bancaria, FluBot se ne accorge, ruba il nome
utente e la password e intercetta l’SMS che contiene la password aggiuntiva
temporanea necessaria per validare la transazione. Fatto questo, ha tutto il
necessario per prendere il controllo del conto corrente della vittima e
consegnarne il contenuto ai criminali informatici che gestiscono il virus.
Già che c’è, FluBot usa la rubrica telefonica della vittima per trovare nuovi
bersagli, esattamente come faceva Iloveyou, e questo gli consente di
propagarsi in modo esplosivo.
Rimuovere FluBot dal telefonino, inoltre, non è facile: non basta togliere
l’app ma è necessario un riavvio in Safe Mode, una procedura che è
meglio affidare a mani esperte.
C’è anche un altro parallelo con quell’attacco di due decenni fa: FluBot può
colpire soltanto se l’utente clicca sul link presente nel messaggio, proprio
come avveniva con lloveyou. Senza questo primo gesto, l’attacco fallisce.
FluBot e Iloveyou sono accomunati anche da un’altra peculiarità: funzionano
soltanto su alcuni tipi specifici di dispositivi molto diffusi. Iloveyou
poteva agire soltanto sui popolarissimi sistemi Windows 95 che usavano
Outlook; non aveva alcun effetto sui computer MacOS o Linux. Allo stesso modo,
oggi FluBot colpisce soltanto gli smartphone, e specificamente gli smartphone
Android; non ha effetto sui telefonini non smart e sugli iPhone.
L’attacco di FluBot, quindi, ha effetto soltanto se si verifica una catena ben
precisa di errori dell’utente:
la vittima si fida del messaggio di invito, pensando che provenga da un suo
conoscente fidato;
clicca sul link presente nel messaggio;
scarica e installa un’app non ufficiale senza chiedersi come mai non è
presente negli App Store normali;
e usa uno smartphone Android senza proteggerlo con un antivirus
aggiornato.
Se manca uno solo di questi anelli della catena, l’attacco fallisce.
Oggi come allora, insomma, difendersi dagli attacchi informatici più diffusi è
soprattutto questione di emozioni, di psicologia più che di tecnologia. E
siccome la psicologia umana non cambia e non si aggiorna, certe trappole
funzionano sempre e continueranno a funzionare.
La differenza è che adesso le trappole psicologiche vengono usate dal crimine
organizzato, mentre vent’anni fa Onel de Guzman era semplicemente uno
smanettone che voleva usare Internet a scrocco. E la sua esca psicologica era
altrettanto semplice: il bisogno universale umano di sentirsi amati da
qualcuno.
---
Informazioni su FluBot e istruzioni per riconoscerlo e rimuoverlo
Guida
dell’operatore telefonico svizzero Salt (in italiano).
Il podcast del Disinformatico della Rete Tre
della Radiotelevisione Svizzera ha un paio di novità: da oggi esce in leggero anticipo rispetto al passato, alle 9 del mattino del venerdì, e prossimamente (dal 5 novembre) sarà regolarmente in versione Story, ossia dedicata a un singolo argomento approfondito, come già fatto sperimentalmente quest’estate con ottimi risultati di ascolto. Se avete un argomento da proporre o una storia informatica che vorreste sentirmi raccontare, i commenti sono a vostra disposizione.
La puntata di oggi, condotta da me insieme ad Alessio Arigoni, copre i seguenti
argomenti, con i link ai rispettivi articoli di approfondimento:
È disponibile il podcast di oggi de Il Disinformatico della Rete Tre
della Radiotelevisione Svizzera, condotto da me insieme ad Alessio Arigoni. Questi sono gli
argomenti trattati, con i link ai rispettivi articoli di approfondimento:
È disponibile il podcast di oggi de Il Disinformatico della Rete Tre
della Radiotelevisione Svizzera, condotto da me insieme ad Alessio Arigoni. Questi sono gli
argomenti trattati, con i link ai rispettivi articoli di approfondimento:
È disponibile il podcast di oggi de Il Disinformatico della Rete Tre
della Radiotelevisione Svizzera, condotto da me insieme ad Alessio Arigoni. Questi sono gli
argomenti trattati, con i link ai rispettivi articoli di approfondimento:
È disponibile il podcast di oggi de Il Disinformatico della Rete Tre
della Radiotelevisione Svizzera, condotto da me insieme ad Alessio Arigoni. Questi sono gli
argomenti trattati, con i link ai rispettivi articoli di approfondimento:
È disponibile il podcast di questa settimana de Il Disinformatico della Rete Tre
della Radiotelevisione Svizzera, condotto da me insieme ad Alessio Arigoni. Questi sono gli
argomenti trattati, con i link ai rispettivi articoli di approfondimento:
È disponibile il podcast di oggi de Il Disinformatico della Rete Tre
della Radiotelevisione Svizzera, condotto da me insieme ad Alessio Arigoni. Questi sono gli
argomenti trattati, con i link ai rispettivi articoli di approfondimento:
È disponibile subito il podcast di oggi de Il Disinformatico della Rete
Tre della Radiotelevisione Svizzera, condotto dal sottoscritto: lo trovate
presso
www.rsi.ch/ildisinformatico
(link diretto). Questa è l’edizione estiva,
dedicata all’approfondimento di un singolo argomento.
Buon ascolto, e se vi interessano il testo e i link alle fonti della storia di
oggi, sono qui sotto!
Nota: la parola CLIP nel testo che segue non è un segnaposto in
attesa che io inserisca dei contenuti. Indica semplicemente che in quel punto
del podcast c’è uno spezzone audio. Se volete sentirlo, ascoltate il podcast
oppure guardate il video che ho incluso nella trascrizione.
---
[CLIP: (in sottofondo) Materia oscura]
No, non state ascoltando il mio gatto che si è addormentato sulla tastiera
musicale o la produzione di qualche compositore di musica d’avanguardia:
questa è letteralmente la musica delle sfere, come l'avrebbero chiamata i
filosofi.
Si tratta di suoni generati partendo dai dati astronomici che hanno
fornito la prima prova diretta dell’esistenza della materia oscura, quella
sostanza per ora misteriosa che compone la stragrande maggioranza della
materia presente nell’universo. Questi suoni rivelano armonie e correlazioni
che sfuggirebbero ad altri modi più tradizionali di rappresentare gli aridi
dati scientifici. Sono un esempio di sonificazione.
Può sembrare un concetto informatico molto astratto, ma la sonificazione è
invece estremamente concreta. Vi faccio un esempio per chiarire cosa intendo.
[CLIP: Geiger]
L’avete riconosciuto? È il suono di un contatore Geiger. Il numero e la
rapidità dei clic che sentite indicano molto chiaramente se si è in presenza
di una sorgente radioattiva e quanto è pericolosa, senza doversi distrarre a
guardare uno schermo. Anche questa è sonificazione.
[SIGLA]
La storia della sonificazione nasce appunto in sostanza con il contatore
Geiger, inventato nel 1908 dal fisico tedesco Johannes Wilhelm Geiger. Serviva
un modo semplice e pratico di rappresentare un’informazione complessa, e il
suono si prestava perfettamente allo scopo.
Siamo abituati a vedere dati sotto forma di grafici o numeri su un contatore o
su un quadrante, ma percepire i dati tramite i suoni offre vantaggi di
facilità e precisione nella comprensione: il nostro orecchio percepisce con
estrema finezza, per esempio, le differenze di tempo, di frequenza e di
volume.
Prendete gli ossimetri o saturimetri, quei sensori che in campo medico si
applicano alle dita per misurare la saturazione dell’emoglobina nel sangue e
quindi stimare la quantità di ossigeno presente in circolo. Spesso indicano le
pulsazioni e la saturazione usando dei toni che variano di frequenza a seconda
della percentuale di saturazione.
Oppure considerate un altro oggetto abbastanza curioso: il variometro. Se
avete mai provato l’ebbrezza di un volo in aliante o in parapendio,
probabilmente questo suono vi sarà familiare:
[CLIP: Variometro]
Il variometro indica la velocità di salita o di discesa sotto forma di suoni,
così il pilota può usare l’udito per avere quest’informazione preziosa senza
impegnare la vista guardando un numero su uno schermo o su un quadrante.
Se preferite tenere i piedi per terra e guidate un’automobile recente, avrete
dimestichezza con un altro tipo di sonificazione:
CLIP: auto-parcheggio
I sensori di parcheggio delle auto rappresentano la distanza dagli ostacoli
tramite dei bip sempre più frequenti man mano che ci si avvicina. Con la
diffusione dell’informatica, la sonificazione ha preso sempre più piede ed è
diventata sempre più sofisticata. Oggi permette, per esempio, ai non vedenti o
ipovedenti di capire l’andamento e i dettagli di un fenomeno o di una serie di
dati che solitamente verrebbero presentato come grafico e quindi sarebbero
inaccessibili.
Per esempio, come si può mostrare o descrivere un cielo stellato a chi non lo
può vedere? Questa che state per sentire è la sonificazione, realizzata dalla
NASA, di un’immagine del centro della nostra galassia, “vista” per così dire
simultaneamente nelle sue emissioni in luce visibile, in raggi X e in
radiazione infrarossa:
Questi suoni sono una scansione, da sinistra a destra, di questa immagine: le
tonalità e l’intensità dei suoni rappresentano la posizione e la luminosità
delle singole stelle. Un orecchio sensibile e allenato riesce a ricostruire la
scena partendo da questi suoni e riesce ad acquisire grandi quantità di dati
in pochissimo tempo.
Chi avrebbe mai detto che dei semplici dati scientifici avrebbero potuto
generare un’armonia così eterea?
Ma non sempre i suoni delle sonificazioni sono così armoniosi e rassicuranti.
Questa sonificazione rappresenta un anno di terremoti in Giappone, indicandone
localizzazione, intensità e profondità, limitandosi soltanto alle scosse di
magnitudo 3 o superiore.
[CLIP: Terremoti]
All’inizio questi suoni rivelano con grande chiarezza quanto siano frequenti i
terremoti e di conseguenza quanto siano assurdi i vari tentativi delle
pseudoscienze e dei mistici di correlarli ad allineamenti planetari o astrali.
Poi arriva la grande scossa, e quel ribollire che ci aveva impressionato
all'inizio assume tutt'altra proporzione.
Un grafico non avrebbe reso così chiaramente la potenza del fenomeno. Ed è
proprio a questo che serve la sonificazione: a farci capire meglio il mondo,
fragile e potente, nel quale viviamo.
È disponibile subito il podcast di oggi de Il Disinformatico della Rete
Tre della Radiotelevisione Svizzera, condotto dal sottoscritto: lo trovate
presso
www.rsi.ch/ildisinformatico
(link diretto). Questa è l’edizione estiva, dedicata all’approfondimento di un singolo
argomento.
Buon ascolto, e se vi interessano il testo e i link alle fonti della storia di
oggi, sono qui sotto!
Nota: la parola CLIP nel testo che segue non è un segnaposto in
attesa che io inserisca dei contenuti. Indica semplicemente che in quel punto
del podcast c’è uno spezzone audio. Se volete sentirlo, ascoltate il podcast
oppure guardate il video che ho incluso nella trascrizione.
---
CLIP: (in sottofondo) Rumore di apparecchio per tatuaggi
Roy Healy è un ingegnere informatico di Cork, in Irlanda. Nel 2019 ha deciso
di farsi fare un tatuaggio un po’ particolare: un codice QR. Uno di quegli
onnipresenti quadratini bianchi e neri con puntini messi apparentemente a
casaccio che oggi troviamo sui prodotti, sui cartelloni pubblicitari, sulle
fatture, sugli scontrini, nei ristoranti al posto del menu cartaceo e anche
sui cosiddetti “green pass” (più propriamente
“certificati Covid digitali”).
Il signor Healy dubitava che il suo codice QR tatuato sull’avambraccio potesse
funzionare, e si era quindi preparato a presentarlo come una
“affermazione dell’arroganza del tentativo di mescolare tecnologia e
biologia”, ma ha scoperto con piacere che il codice è perfettamente leggibile
nonostante sia disegnato su una superficie così irregolare ed elastica come la
pelle. Il suo codice QR contiene un link che porta di volta in volta al suo
blog, al suo profilo LinkedIn o alle regole di un gioco, come spiega in un’intervista al New York Times.
Molti
trovano
i codici QR insopportabilmente
brutti
e li chiamano“vomito di robot”. Ma belli o brutti che siano, indubbiamente funzionano, costano pochissimo e
sono sorprendentemente resistenti. Questa è la storia della loro nascita e di
come una semplice chiazza di puntini riesce a creare un ponte fra il mondo
reale e quello digitale.
---
SIGLA
La storia dei codici QR inizia in Giappone nel 1994, come evoluzione dei
codici a barre. Prima che arrivassero i codici a barre, gli addetti alle casse
dei supermercati erano costretti a digitare a mano, uno per uno e per ore di
fila, i prezzi di ciascuno dei prodotti acquistati dai clienti. Risultato:
sindrome del tunnel carpale diffusissima, con dolori e perdita di sensibilità
alle mani.
CLIP: registratore di cassa vecchio stile
L’introduzione dei codici a barre, che potevano essere letti dal registratore
di cassa usando un semplice scanner, alleviò moltissimo il problema oltre a
ridurre le code alle casse.
CLIP: registratore di cassa moderno
I codici a barre, però, potevano contenere poche informazioni: una ventina di
caratteri alfanumerici al massimo. In Giappone serviva un modo per poter
rappresentare anche i caratteri Kanji e Kana, e così
Masahiro Hara, che lavorava presso la Denso, una società del gruppo Toyota, sviluppò il
codice QR. Le lettere “QR” significano Quick Response, ossia
“risposta rapida”, perché il codice QR è in sostanza un codice a barre
più capiente e più veloce da leggere.
Questa velocità maggiore è consentita da un paio di trucchi tecnici.
Attenzione: state per entrare in zona nerd. Tra pochi minuti saprete anche
troppo sui codici QR, ma non vi preoccupate: potrete sempre usare queste
conoscenze come arma segreta per troncare qualunque conversazione
indesiderata. Se qualcuno attacca bottone con voi in treno o in aereo e non vi
lascia in pace, lanciatevi in un’appassionata dissertazione sui dettagli del
funzionamento dei codici QR. La persona che vi sta scocciando si pentirà
rapidamente di avervi importunato.
Detto questo, prendete un codice QR, uno qualsiasi, e guardatelo. Sembra un
caos indecifrabile, ma in realtà contiene molti elementi che anche noi umani
possiamo decodificare.
Un codice QR mostra i tre quadrati che formano il finder pattern. Credit:
Wikipedia.
Per esempio, noterete subito che il codice QR contiene tre quadrati con un
quadratino al centro, che delimitano tre dei quattro angoli del codice. Questi
quadrati fanno capire allo scanner (o all’app di lettura presente nel vostro
smartphone) che in quella zona c’è un codice QR. I quadrati sono tre e non
quattro per consentire allo scanner di capire come è orientato il codice e
quindi in quale direzione vada letto. Masahiro Hara scelse proprio un quadrato
con un quadratino al centro, invece di un’altra forma, perché era quella che
più difficilmente poteva comparire per altri motivi su una confezione, un
documento o un modulo: lo scoprì in maniera manuale, passando giorni e giorni
a sfogliare riviste, volantini e scatole di ogni genere in cerca di forme
semplici che non comparissero mai.
Nel codice QR c’è spesso anche un altro quadratino, più piccolo, a volte
presente in più di un esemplare: serve per consentire allo scanner di
correggere la distorsione dell’immagine se il codice viene visto di sbieco o è
stampato su una superficie non piatta, come l’avambraccio tatuato del signor
Healy. E se guardate bene troverete anche un altro schema nascosto: gli angoli
più interni dei tre quadrati di orientamento sono collegati da una riga e una
colonna di puntini alternati bianchi e neri perfettamente regolari, a
differenza di tutto il resto dei puntini.
Anche questa riga e questa colonna servono allo scanner per capire le
dimensioni e proporzioni del codice e correggerne le distorsioni di
inquadratura. Altre informazioni sul formato e sul tipo di dati sono indicate
nelle righe e colonne adiacenti ai quadrati di riferimento. Insomma, c’è molto
ordine nel caos apparente di questi puntini.
Tutto questo è molto ingegnoso, certo, ma il secondo trucco è quello più
potente. Provate a coprire un angolo di un codice QR, oppure prendetene uno
stampato male o danneggiato: lo scanner riuscirà quasi sempre a decodificare
lo stesso il contenuto del codice. È come avere un libro magico nel quale una
pagina di cui una parte è stata strappata via riesce comunque a mostrarvi le
parole mancanti.
Questa umile macchia d’inchiostro riesce a sopravvivere a molti danneggiamenti
perché usa la correzione d’errore: della matematica piuttosto complessa,
sviluppata
nel 1960 da Irving Reed e Gustave Solomon presso un centro di ricerca militare
del MIT, in Massachusetts, che include nella mappa di puntini alcuni dati di
controllo. Questi dati dicono cosa ci deve essere scritto nei puntini
precedenti. Se quei puntini non sono leggibili, per esempio perché sono stati
danneggiati, cancellati o coperti, la correzione d’errore permette di
ricostruire l’informazione mancante. Questo è molto utile negli ambienti nei
quali si usano i codici QR, che sono soggetti a graffi, ammaccamenti,
cancellazioni e abrasioni.
Semplificando moltissimo, immaginate che i dati da proteggere siano i numeri
1, 3, 5 e 11: la correzione d’errore aggiunge l’informazione “il totale dei
numeri precedenti deve essere 20” e quindi se uno dei numeri risulta
illeggibile è possibile dedurlo. Questo è solo un esempio grossolano: la
matematica della correzione d’errore nei codici QR è molto, molto più
complessa, ma il concetto di base è lo stesso.
Resistenza ai danni e
matematica militare: niente male, per un semplice quadratino stampato, vero?
Questa correzione d’errore ha anche una conseguenza estetica poco conosciuta:
siccome i dati registrati nei codici QR sono appunto ricostruibili anche se il
codice è parzialmente danneggiato, è possibile produrre dei “danneggiamenti” artistici: per esempio, si può inserire un logo al centro o in un angolo del
codice per personalizzarlo o abbellirlo, oppure si possono cambiare alcuni
colori o inserire dei simboli all’interno dei quadratini di riferimento, e il
codice risulterà leggibile lo stesso.
Il prezzo di questa miglioria estetica è
una minore resistenza dei codici QR “artistici” ai danneggiamenti, ma se
l’ambiente in cui vengono usati non è troppo ostile è un compromesso
accettabile.
I codici QR possono inoltre contenere moltissime informazioni: fino a 7089
numeri oppure 4296 caratteri alfanumerici o 1817 simboli Kanji o Kana. Per
fare un esempio concreto, due soli codici QR conterrebbero tutte le parole di
questo podcast. Un bel passo avanti, rispetto alla ventina di caratteri dei
vecchi codici a barre.
Robusto, capiente, compatto, economico e facile da stampare ovunque e da
leggere con gli smartphone: non sarà un capolavoro di estetica, ma il codice
QR fa bene il proprio lavoro e inquina molto meno delle soluzioni alternative,
come per esempio i microchip usa e getta. Soprattutto, ci dà un’occasione per
scoprire quanta complessità matematica e informatica c’è dietro gli oggetti
apparentemente più semplici che usiamo tutti i giorni.















{kind=link}
{kind=link}
{kind=link}
{kind=link}