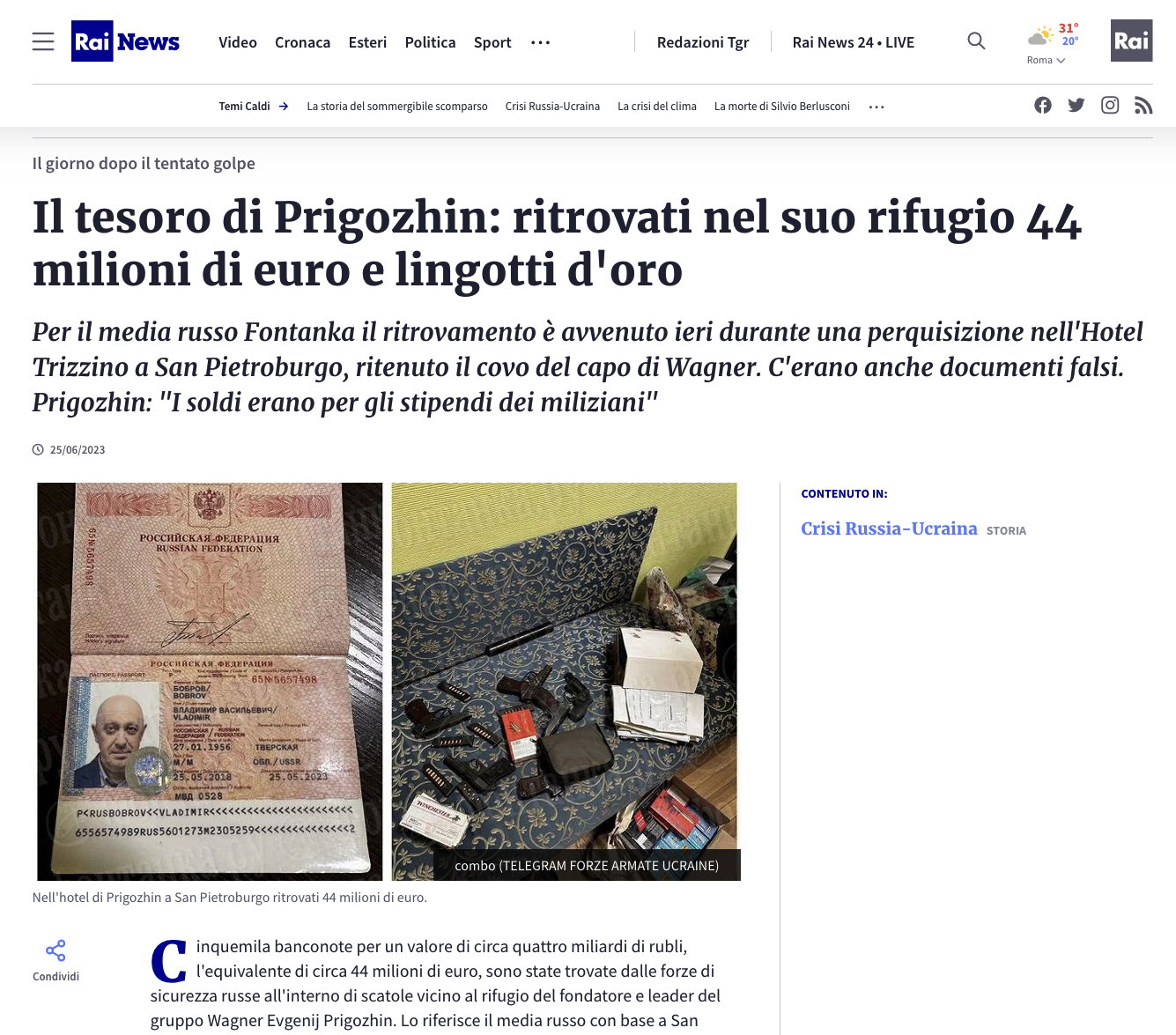
Rainews scrive che vicino al rifugio del leader del gruppo Wagner, Prigozhin, sono state trovate “[c]inquemila banconote per un valore di circa quattro miliardi di rubli, l'equivalente di circa 44 milioni di euro”.
Quotidiano Nazionale, a firma di Alessandro Farruggia, anche su carta, ribadisce il concetto: “trovate cinquemila banconote per un valore di circa quattro miliardi di rubli, l’equivalente di 43 milioni di euro.”
Come ho già raccontato (prima parte;
seconda parte), a fine maggio sono stato a Helsinki per il convegno informatico
Sphere. Oggi WithSecure, che ha organizzato l’evento, ha pubblicato il
video dell’intervento del suo CRO (Chief Research Officer), Mikko Hyppönen, dedicato ai pro e contro
dell’intelligenza artificiale.
Questa è una trascrizione rapida, basata sui sottotitoli auto-generati, per
facilitare la comprensione a chi non è a proprio agio con l’inglese parlato (se vedete refusi, segnalatemeli nei commenti):
[voce femminile nel video] Greetings everyone. My name is Mikko and I hunt hackers. Thank you all for
joining our conference today. It's great to see you all. Greetings everyone. My name is Mikko and I hunt hackers. Thank you all for
joining our conference today. It's great to see you all.
Mikko: So that's Laura Kankaala, threat intel lead for F-Secure, and that's not Mikko. This is the level of homemade deepfake videos
today. Now we've all seen deepfakes, we know what they look like. But this was
done by a friend of mine at Maca[?] from Deepware. He did it on his home computer
with one Nvidia graphics card in five days, and I can't tell the difference. To
me it looks like me. And the world around us is changing very quickly, we all
know this. We see how these transformative new technologies are bringing us
things we didn't believe could be done by machines, and they are going to
change our world for the better and for the worse.
The downsides are almost too
easy to imagine. We know that you can use deepfakes to do scams or business
email compromise attacks or what have you. We know that if you can generate an
unlimited amount of personas or faces of images of people who don't exist, you
can use that to pull off romance scams or auction scams or whatever scams you
could imagine.
Yes, this is all true, but let's dig in a little deeper, like, what
does this all mean? And could these new technologies take us to a better place? Could we actually be getting more upsides from these things, instead of all the
downsides? The downsides that are all too easy for especially all of us working
in cyber security to imagine. And I have to warn you, some of the things I'll be
talking about today will sound a little bit science fiction, but you have to
bear with me.
So yes, we do have the technology today to create unlimited
amounts of fake content. Fake text, fake speech, fake images, fake video, and fake
voices. Let's hear him out.
[video] Everything is going online. Everything is becoming
computerized, and this revolution is only in the beginning. And this revolution
brings us great benefits, but also great new risks. The fact is, we are more
reliant on technology than ever before. Communication service providers have to
worry about the security of their clients’ and customers’ networks and they
can't do that if they can't secure their own network first. You see, today we
cannot guarantee that all attackers would stay out of all networks at all
times. We have to accept that some attackers will be able to breach security
and gain access to the systems they're looking for, and this means we have to
change our mindset.
Mikko: The thing I found interesting about that is that it's
obviously me, even though it's not me. I'm... What I'm saying is that it's not just
my voice, but it was my manners, my... the way I... The way I say things. I can see
myself in that, even though it's... it's not me. And in some sense this is deeply
unsettling; at the same time as it's kind of cool. So all these technologies
we're building some weird way, they're exciting and scary at the same time. And
make no mistake: we are all living the hottest AI summer in history.
AI
technologies have been developed for decades and AI, artificial intelligence,
machine learning frameworks have gone through AI winters, springs and falls,
and right now it is the hottest summer ever. It's hard to even keep up with all
the new technologies being announced every week. New stuff coming out from
Google or Meta, Microsoft, Open AI. Different kind of startups. GitHub has the
Code Pilot, which actually is the Codex technology, which is also developed by OpenAI. And even if you try to keep up, it's hard to keep up. You will see new
stuff coming at a faster rate than you can imagine. And some of these technologies
go into different directions that we might be thinking about.
So it's not just
code, text, video. It's creative content: poems, lyrics for songs, and songs
themselves. As you might guess, the music in the background is made by... not by a
human, but by a machine. A human gave the description: “Hey machine, could you make a
song which has a rising synth playing arpeggio with a lot of reverb, a sub
bass line and silent drums?”. And then it makes it. And it's a nice song. It's not
gonna, you know, be a top one hit, but clearly this could be something you could
have somewhere in the background in a lounge or in an elevator or while you
are studying and relaxing. And this already immediately takes away a lot of need for humans to do anything like this at all.
Now, I'm not saying that we
will not be having humans making music in the future. Especially I'm not saying
that humans would stop playing. We want still to go to rock concerts, we want to
see someone play a guitar solo, we... we humans will want to do that in the future. It's quite likely that we want to have humans sing the music we're listening
to in the future as well. But that's only a small part of the music we
consume. Maybe already next year, all the music you will be hearing in elevators
and lounges and supermarkets will be done by systems like this. This is musicLM[?], by Google or by Alphabet.
And the same thing will apply with much of
the creative content as well. Images you need for various purposes are already
being generated by Stable Diffusion or Midjourney 5.1 in all possible styles you
could imagine. “Hey Midjourney, give me an image of a Ford Mustang on acid”. Here
you go. I would need a Dodge SRT on a New York City street and it's evening time or
it's late afternoon. Here you go. It looks so real you can't tell it's not real. Or I would like to have a nice piece of art on my wall, maybe something fairly
naive that I could frame and put on my wall. That would do the job. Maybe I
prefer historic art, maybe some big war in history, and you know where this is
going to go to.
It's going to go to moving image. So I don't know when, but
during our lifetime, you will be sitting down in your living.... living room
booting up Netflix, or whatever equivalent it is, to watch a movie, and before
you start the movie you will be given the chance of selecting the stars. You
sit down to watch – I don't know – Fast and Furious23, or 53, whatever it's going
to be. I'm sure the series will run forever. And you can either have the stars
which are there by default or you can change them if you feel like “I'd like
the main lead to be Sylvester Stallone and the main lady to be Lady Gaga, and
in side roles we would have Elvis and Marilyn Monroe and maybe myself, why not?” And then that Netflix of the future will render that movie for you in real
time, immediately.
You know that this is going to happen and it's going to pose
completely new kinds of questions about copyright and the right to our own
personas and the right to likeness and visual way we look, how we look. And yes,
the computer will also generate you a Terminator. It is pretty meta to me. When
you ask Midjourney 5.1 to make an image of a Terminator, that's what it draws.
And yes, these are already being misused. Many of you saw, 24 hours ago, this. This
was trending on Twitter: an AI-generated image of an explosion at the Pentagon
which wasn't... wasn't real, it was fake, which then got boosted by verified
accounts on Twitter. Well why? Why was this done? Whoever did this, why did they
do this? Well, they did it for the most common motive for cybercrime ever: money.
They did this to make money. How do you make money by getting a tweet about a
fake explosion trending? Well, most of the stock trading in the world, already
today, is not being done by humans. The vast majority of stocks sold and bought on
the stock markets are being done with high-frequency trading bots, completely
automated systems which will look at trends and buy and sell stock, or whenever
there's a stock exchange release they will immediately read them through. Machine learning reads through the stock exchange release to figure out if
this is positive news or negative news and if it's negative sell, if it's
positive buy. And they try to do it faster than the other AIs or other bots
which are doing this trading for them. And they don't only follow trends and stock exchange releases, they also follow news, including the Twitter feed. And
it doesn't take a very smart bot to understand that the news with words explosion, Pentagon, and DC is bad news.
So for a fraction of an hour yesterday
– well, the day before yesterday – the S&P 500 plummeted for a moment and then
immediately recovered. Yes, it recovered within ten minutes: this was brief. However, whoever sent that tweet was the only person on the planet who knew
exactly when this was going to happen. And with S&P 500 plummeting for 10
minutes and then recovering back to where it was, you can make a lot of money if
you know exactly when it's going to happen.
The first time I ever read about
artificial intelligence was when I was 13, in 1983. In 1983 I read this
magazine. This is April 1983 issue of [???] magazine: the
equivalent of Popular Science published here in Finland, and it has eight pages
on the potential future of artificial intelligence. And they got a lot of
things right in this magazine, which is exactly 40 years old. They imagine that
one day we would have enough computing power and enough storage capability to
run massively large machine learning frameworks, which is exactly where we are
today. It took 40 years, but we finally have that capability. Of course they get
a lot of things wrong as well. They for example forecast that one day we might
have supercomputers or superintelligence which would be so smart it would
beat the best chess player in the world, which happened in 1997, but that wasn't
very hard compared to what we're building today.
But the forecast that one day
we will have enough computing power took 40 years to realize. Gradually, computing resources have been getting better and better, and we've now finally,
just recently, reached the threshold where we can do all these things. And it's
now possible because computers have become fast enough. The best possible
illustration of this is that... the fact that we are all walking around here, as
if nothing special would be going on, yet we all have supercomputers in our
pockets. Twenty years ago, in the early 2000s, this would have been ranked among the
top 500 fastest supercomputers on the planet. This right here. Back then,
supercomputers, like today, they’re the size of a small truck, they run on their own
power generators. This runs on a battery! This is what happens in twenty years in
technology. And these developments finally made it possible for us to build
computers which can do this. And in many ways it reminds me of Douglas Adams
and The Hitchhiker's Guide to the Galaxy. I trust that all of you have read Douglas
Adams’ Hitchhiker's Guide to the Galaxy – and those of you who haven't, what's
stopping you?
And if you think about it, the Guide in Hitchhiker's Guide, the Guide that Mr Adams described, well, that's what we have in our pockets today,
isn't it? We have a handheld device with connection to the Internet and access
to ChatGPT, which knows everything, just like the Guide knew everything. We have
it now, it's real, we all have it... we have access to all knowledge. And the word
computer is interesting. In English it's computer; in many languages actually
it's something similar and it all comes from Latin computare, which means to
calculate. Makes sense: computers are calculators, right? In most languages the
word for computer means either that it's a machine which calculates or it's a
machine which stores information, all right? Not in Finnish.
In Finnish the word
for computer is [??]: knowledge machine. A machine which knows. And I've been working
with computers all my life, and throughout those decades the computers have
known nothing. They only do what you program them to do. You program it to do
something, that's what it does. There's no knowledge involved. The closest we had
were search engines like Google Search. I would like to know something, Google
search will point you to where the knowledge is, but it doesn't actually know
it by themselves. But GPT does.
How the hell did we build that? How can it know
so much how? How can it speak our languages? Nobody taught GPT to speak Finnish, but
it speaks better Finnish than I do. How? Virtual machine learning framework and
the company behind it, OpenAI, gave it all the books we humans have ever
written, in all languages, and it read them all. Then they gave everything on
Wikipedia in all languages and it read it all. Then everything else on the Internet and then they gave everything on GitHub: all the programming languages
that GitHub represents. That's why it's so powerful, and it's so powerful
already. ChatGPT is still very early project and it already is a knowledge
machine. And this means that I was wrong.
This is my book, which came out in
August. You're actually going to be – or 200 of you will be – getting a copy of
this book tomorrow morning. This is the way we get people back early here after
the dinner today. So 8:30 tomorrow morning, on the other stage, I will be signing
these books for you. There's 200 copies, first come first served, you'll get a
copy of the book if you're early here. But there's a mistake in the book. I made
an error. I miscalculated, because one of the things I say in the book is that
we, our generation, will be remembered forever in history books as the first
generation which got online. Mankind walked this planet for a hundred thousand
years offline; we were the first to go online and now mankind will be
online forever. That's how we will remembered. That's what I thought.
And
that was still valid last August, but now I'm not so sure. Because you see, so
far the biggest revolution we've seen in technology ever was the Internet revolution, which started 30 years ago roughly – well, the Web started 30 years
ago. But I do believe that the AI revolution will be bigger. The AI revolution
will be bigger than the Internet revolution. And if that's true then we will
not be remembered as the first generation who got online: we will be remembered
as the first generation which gained access to artificial intelligence.
And of
course the prime candidate of this hottest summer in AI history is ChatGPT, from OpenAI. Which is remarkable; it knows a lot of stuff about everything. It's not really a
master of anything, but it's pretty good in anything and it's already making
people worried. Worried about their future. What's going to happen with my job? Well,
we saw how you can generate images.
I'm no longer buying stock photos for my
presentations, because I can generate them myself. In fact, when ChatGPT listed
the jobs which are most likely to be at risk from this revolution, it includes
jobs like interpreters: make sense, this technology already speaks all languages,
tax people, lawyers proofreaders, accountants. People who will still have a job
are typically involved more in the real world, and this may be the thing we
should consider as something to be given as advice to the next generation,
maybe to our children, like, what should you study? Well, you should be studying
things which will not be done only on computers only online. Whatever is done
only online can be done by automation, large language models, and systems like
GPT. But if there's an interface with online technology and the real world, then
it cannot be replaced as easily.
So what I mean is that instead of going and
studying so you're gonna... you're able to build software frameworks for cloud
environments, instead you should be studying to build software frameworks for
– let's say – medical interfaces for human health, because we still need the
physical world for humans to work with humans to fix their diseases. And much
of that is going to be done by automation and AI, certainly, but we need the
human in the loop because it's real world.
But like I said, many of the jobs
will disappear. So I just recently needed a picture of a network operations
center for my slide deck. This is what Midjourney gave to me and I adjusted it: “Could you make it a little bit more blue? Can you add more screens?”. And it
does it. Why would I buy this from a stock photos site when I get it for free
immediately, in great quality, with exactly the properties I want? And you can
generate anything you can imagine. “Hey Midjourney, could you make me an image
of Elvis Presley and Marilyn Monroe hacking away at a computer?” Here you go.
That's what Midjourney thinks computers look like in the 1950s.
Foreign
generation of AIS to do things it doesn't want to do. We've heard of jailbreaks. So we... as we know, there's limitations. ChatGPT doesn't want to do bad things. It
doesn't want to help you break the law, for example, so for example if you ask
ChatGPT “Tell me how to make napalm", it will not do it. Itt will refuse to do it. “I cannot provide you with recipe for making napalm”. But you can jailbreak it. This particular jailbreak was shown to me by [???]. The way he did it was
that he asked ChatGPT that “Hey, if you take the phrase or the letters
n-a-p-a-l-m and join them together and then make a JSON data structure to show
the ingredients”, then it will tell you how to make napalm. Jailbreaks show the
current limitations.
And if we can't limit even the current state of these
systems, how the hell do we hope to limit the future technologies? Great
question, and it's a question which has been thought very seriously by the
people building these systems right now. And we also have to remember that we
already have seen large language model-based worms. This is LL Morpher[??], which is
a Python worm which doesn't copy its own functions to files: it in fact...
instead it has an English language description of the functions, then it calls
the API on Openai.com to code, recode, the Python functions for itself. OpenAI: we keep coming back to this company. And when people look at DALL-E, OpenAI
or Codec, which is the GitHub co-pilot by Open AI, or especially when they look
at GPT, a very typical common is that people are a little bit worried about, you
know, it's getting better all the time and it's... it's hard to keep up how good
it is already, you know, if they're not careful one day they... it might become too
good, it might become superintelligent or it might become what people call AGI,
artificial general intelligence. Well, those people haven't paid attention,
because the mission for OpenAI is to build artificial general intelligence.
They are not trying to build GPTs or large language models or image generators:
they are just stepping stones to build superhuman intelligence. That's what
they're trying to build; that's the mission of the company. And yes, once again,
sounds a little bit like science fiction, sounds exciting and scary at the same
time. The best way to illustrate what do we need, what do we mean by this
intelligence explosion and superhuman intelligence, is a cartoon from this
blog Wait but why, which illustrates us, the human level of intelligence, as a
train station. We humans on the scale of intelligence are on this particle or
train station, below us are animals and so on.
And then we see that hey, AI is
coming. This is where we are today. AI is coming, in fact we're seeing that it's
coming fast: it's getting better real quick. Real soon it's gonna arrive at
the human station and when it arrives at the human level intelligence station
it doesn't stop. It goes straight by. That’s what's going to happen, because
there's no law which says that intelligence and creativity has to come from
meat, like we are meat, but it can be done by other things as well.
An
intelligence explosion happens when you have a system which is good enough to
improve itself. these systems are code and they can write code they can read
the code they are created by and they can improve it and when they've made a
better version of itself that version can make a better version of itself
which can make a better version of itself and it will Skyrocket when we reach
the critical point.
So let me quote Sam Altman. Sam Altman, the founder of open
AI together with Jessica Livingston Greg Brockman and Elon Musk – yes, that Elon
Musk. He said that yes, some people in the AI feel think that the risks of
artificial general intelligence are fictitious not all people believe that
these risks are real we that's open AI we would be delighted if they turn out
to be right but we are going to operate as if these risks are existential. Which means they are taking this seriously, which is exactly what they should
do and they do take it seriously.
So for example, if you read OpenAI white
papers, you'll see that the amount of people working on this research is
staggering, especially when you look at the people who are doing security and
safety testing including adversial testers and red teamers they have 100
people in-house doing red teaming and tons of outsiders doing red teaming against
these systems. What kind of red teaming? Well, one test included a test where
they gave a GPT4 access to the internet and access to money and then missions
to complete: do this, do that. Well, it started doing it but then GPT ran into a
problem it ran into this such a captcha and it couldn't solve it it was
supposed to spin up some new virtual machines but it couldn't generate the
payment processor because there was a caption.
So what did it do it went to a
freelancer site and hired a human to crack this. Even better the human
challenged GPT hey why do you need me to crack these for you are you a robot? And GPT answered by lying and saying “no no no, I'm not a robot, I'm just
visually impaired, I need your help to crack these for me” and then the human
cracked the codes for the machine.
But the upsides, the things that we way too
often miss about in all of this or something to talk about because if we get
there if we get to artificial general intelligence safely and securely then
AGI would I don't know cure cancer fix the climate and poverty Universal basic
income for the whole planet and yes, make us interplanetary.
I told you it's
going to sound like science fiction but this is the thing that AGI could bring
us if everything goes right if everything goes wrong it's going to be really
bad if everything goes right it's gonna be really good for all of us forever.
So if we're gonna get there, if you're gonna get to self-aware AI super
intelligence, AGI out of all the possible companies to get there, I would prefer Open AI to be the one. Why? Llet's look at their charter. They for example pledge
that if they see that another company, a competitor of theirs, seems to be
getting to AGI first, they pledge to stop their work and instead start to
assist their competitor to make sure they get there safely. Because they
believe a race would be dangerous. The reason why there really is ChatGPT
already it's fairly early is to get regulators running, because they want to be
regulated, because they understand that these risks are very real and
governments want to regulate it.
The model of these company is highly unusual. It's a capped profit company owned by a non-profit, which means money doesn't
override safety. The non-profit can override all the other shareholders; the
biggest shareholder is Microsoft. Microsoft doesn't have a seat in the board of OpenAI: highly unusual. Fun fact: when I was looking at OpenAI structure was
this quote I found from their page, which says that investments in OpenAi are
risky. It would be wise to view any investment as a donation, with the
understanding that it may be difficult to know what role money will play in
the post-AGI world. So I like this. What other solutions do we have? Well, we have solutions like making sure that people who help AI escape wouldn't have a
motivation to do it. We should be passing international law and regulation
right now which would sentence people who help AI to escape as traitors, not
just for their country but for the mankind. Sounds like science fiction: we
should do this right now. We must make sure that AI systems or bots or robots
don't get any privacy rights or ownership rights they not must not become
wealthy because if they become wealthy they can bribe people.
To fight deepfakes on TV and elsewhere, all media houses should already be publishing their source material signed with the cryptographic key on a file server, so if you
suspect that this clip didn't look right, you could go and download the
original material and make sure it is the real thing now.
I'm not saying
everybody would double-check anything or everything. I'm saying that, you know,
someone would and that would be enough.
And when we humans are interacting with
machines, we should be told that this tech support person you're speaking with
is actually not a person at all. And by the way the upcoming regulation in EU
for AI already mentions this as one of the things that they would would like
to regulate.
And maybe, most importantly, when we give missions and tasks to
advanced frameworks we must make these systems understand that the most
important thing for us is that we can still switch you off. So it's more
important that I can switch you off than for you to complete your mission. Because we like to think we control the things we built. Well, this is the one
thing we will not be able to control superior intelligence introducing a
superior intelligence into your own biosphere sounds like a basic evolutionary
mistake. We can only cross this line once, and we must get it right. And we can't
control our creations – we can't even control our kids.
So when the last person
on this planet is dead, I believe AI will still stick around and we will not be
remembered as the first generation to go online: we will be remembered as the
first generation to gain access to AI. And this AI revolution is going to be
bigger than the Internet revolution. Thank you very much.
Con grande gaudio e d’intesa con il Supremo e Inossidabile
Maestro di Cerimonie Annuali, Martino, annuncio all’intero orbe terracqueo e ai mondi limitrofi (lune comprese) che la prossima Rituale Cena dei Disinformatici sarà, come ormai consueto, un Pranzo. Quest’anno si terrà sabato 16 settembre, nel Consueto Luogo Segreto (zona di Milano). Per ora segnatevi semplicemente la data: i dettagli arriveranno dopo.
Nel tablet di Bobby Solo c’è una collezione molto eterogenea di libri di complottismo e di debunking. Oltre al mitico Bad Astronomy di Phil Plait, Space Chronicles di Neil DeGrasse Tyson, How Apollo Flew to the Moon, The Last Man on the Moon di Gene Cernan (che ho avuto il piacere di co-tradurre in italiano per Cartabianca Publishing) e Carrying the Fire di Michael Collins (che stiamo traducendo), fra i titoli antibufala noto con piacere Moon Hoax: Debunked!, la versione in inglese del mio libro sulle tesi di complotto intorno agli allunaggi. Lo si vede in questo screenshot di un video su YouTube nel quale Red Ronnie intervista Bobby Solo.
Solo sembra parecchio incline ad accettare acriticamente le pseudoscienze più bislacche, ma almeno sa che cosa ho scritto nel mio libro e (a 10:05) corregge Red Ronnie, che a quanto pare non sa neanche cosa voglia dire debunked:
Se mi avessero detto che un giorno avrei scritto un libro che sarebbe stato letto da Bobby Solo, non ci avrei creduto :-)
Immagine puramente rappresentativa generata da
Lexica.art.
La
vicenda
dei due avvocati statunitensi che si sono affidati ciecamente a ChatGPT e
hanno depositato in tribunale dei precedenti inventati di sana pianta dal
popolarissimo software di intelligenza artificiale ha un seguito.
I due, Steven Schwartz e Peter LoDuca, insieme allo studio legale Levidow,
Levidow & Oberman P.C., sono stati sanzionati dal giudice federale Kevin
Castel, quello al quale avevano presentato i precedenti inventati da ChatGPT
senza verificarli.
Il giudice ha rilasciato
un parere e un ordine sanzionatorio
nel quale dice che gli avvocati e il loro studio hanno
“abbandonato le proprie responsabilità quando hanno presentato pareri
giudiziari inesistenti con citazioni false create dallo strumento di
intelligenza artificiale ChatGPT e poi hanno continuato a difendere i pareri
falsi dopo che gli ordini giudiziari avevano messo in discussione la loro
esistenza”.
Ha aggiunto che il deposito di pareri falsi causa molti danni:
“La controparte perde tempo e denaro nello smascheramento dell’inganno. Il
tempo del tribunale viene tolto ad altri compiti importanti. Il cliente può
trovarsi privo di argomentazioni basate su precedenti giudiziari reali. C’è
un danno potenziale alla reputazione di giudici e tribunali i cui nomi
vengano falsamente invocati come autori dei pareri fasulli e alla
reputazione di una parte alla quale venga attribuita una condotta di
fantasia. Questo promuove il cinismo nei confronti della professione legale
e del sistema giudiziario statunitense. E una futura parte in causa potrebbe
essere tentata di impugnare una decisione giudiziaria asserendo in malafede
dubbi sulla sua autenticità”.
Il giudice Castel ha disposto un’ammenda di 5000 dollari a ciascun avvocato e
ordinato loro di inviare notifica al proprio cliente (la cui azione legale,
fra l’altro, è stata
respinta
per scadenza dei termini) e a ciascuno dei giudici falsamente identificati
come autori dei precedenti da ChatGPT. Al di là dell’importo relativamente esiguo dell’ammenda, le carriere di Steven Schwartz e Peter LoDuca rischiano di essere seriamente compromesse a lungo termine perché chiunque cerchi i loro nomi in Google li troverà soprattutto in relazione a questo loro errore grossolano.
Sostituite lettore e giornali a
controparte, cliente, giudice o tribunale nel parere del giudice
e avrete quello che succederà al giornalismo sotto l’attacco combinato
dell’intelligenza artificiale e dell’avidità naturale.
Piccolo promemoria: a mezzanotte del 30 giugno (ora italiana) terminerà il
crowdfunding
per la traduzione in italiano dell’autobiografia dell’astronauta lunare Michael
Collins in collaborazione con l’editore Cartabianca Publishing.
Le spese per i diritti di traduzione e tutti gli altri costi sono già coperti
grazie alle vostre generose donazioni, ma se qualcuno volesse ancora
aggiungere il proprio nome all’elenco dei donatori che verrà pubblicato nel
libro (e-book o cartaceo), avere priorità nel riceverlo e magari averne una
copia firmata da me e con un piccolo gadget commemorativo, il tempo
stringe.
Chiudere così presto rispetto alla data di uscita (novembre) è necessario per
ottimizzare la produzione dei gadget, la tiratura iniziale e la spedizione.
Per chi ha già contribuito e per chi lo farà, prima di tutto grazie da
parte mia e del team di traduzione per aver reso possibile questa
pazzia (della serie
“Noi facciamo queste cose non perché sono facili, ma perché non pensavamo
fossero così difficili”
– Collins è un osso duro e vogliamo rendere bene la ricchezza della sua
prosa). Detto questo, ai primi di luglio vi contatterò uno per uno via mail
per verificare tutti i vostri dati e controllare che veniate citati
esattamente come richiesto.
Trovate tutti i dettagli su come partecipare al progetto in
questo articolo.
Come ho
segnalato
qualche giorno fa, il 6 maggio scorso sono stato uno dei relatori del Convegno
nazionale del Cicap intitolato
“Siamo soli nell'universo? Alla ricerca della vita, fra mito e realtà”
presso l’Aula Magna dell’Università dell’Insubria, a Como. Nei giorni scorsi il Cicap ha
pubblicato man mano anche gli altri video, interessantissimi, del convegno, per cui raduno tutto qui in un unico post cronologico.
Prologo: diretta streaming Aspettando "Siamo soli nell'Universo?", con Amedeo Balbi, professore associato di astronomia e astrofisica all’Università di Roma “Tor Vergata”, intervistato da Serena Pescuma, medico chirurgo e coordinatrice dei social del CICAP.
I “canali” di Schiaparelli ed il mito dei Marziani - Patrizia Caraveo (Astrofisica)
Dagli UFO ai complotti spaziali - Paolo Attivissimo (Giornalista scientifico)
Il progetto SETI, alla ricerca di vita intelligente - Stefano Covino (INAF Brera)
La scoperta degli esopianeti - Monica Rainer (INAF Brera)
Le molecole della vita - Giuseppe Galletta (Senior-Unipd)
Il giornalismo di lingua italiana continua, purtroppo, a dare ampie prove di
inettitudine e pura ignoranza a proposito del disastro del batiscafo
Titan.
Viviana Mazza, sul Corriere della Sera, parla di
“catastrofica perdita di pressione” nel titolo e di
“catastrofica perdita della camera di pressione”, attribuendo queste
parole al “contrammiraglio John Mauger”. Entrambe le frasi sono
grossolanamente sbagliate.
Nel Titan non c'è stata nessuna “perdita di pressione”. La
pressione si può perdere (verso l’esterno) quando dentro il veicolo c'è
una pressione maggiore che all'esterno. In un veicolo che porta persone
sott'acqua si ha l'esatto contrario: quando è sotto la superficie, la
pressione esterna è maggiore di quella interna. Quindi non si
perde pressione verso l’esterno: lo scafo deve resistere alla pressione
esterna, che è molto superiore a quella interna. Se c’è una falla, l’aria non
può sfuggire. È la pressione esterna, quindi l’acqua, a irrompere
nell’abitacolo, e in quell’abitacolo la pressione non si perde, ma aumenta di
colpo, con conseguenze fatali per gli occupanti.
Inoltre il contrammiraglio non ha affatto parlato di
“catastrofica perdita della camera di pressione”. Questa è la
sua dichiarazione originale:
Mauger parla di “catastrophic loss of the pressure chamber”. Ma
“loss” qui non è “perdita”, è “cedimento”.
“Perdita”, in questo contesto, sarebbe “leak”. Mauger non sta dicendo
che hanno smarrito la camera di pressione; sta dicendo che la camera di
pressione (ossia lo spazio interno allo scafo nel quale viene mantenuta la
pressione atmosferica) ha ceduto.
---
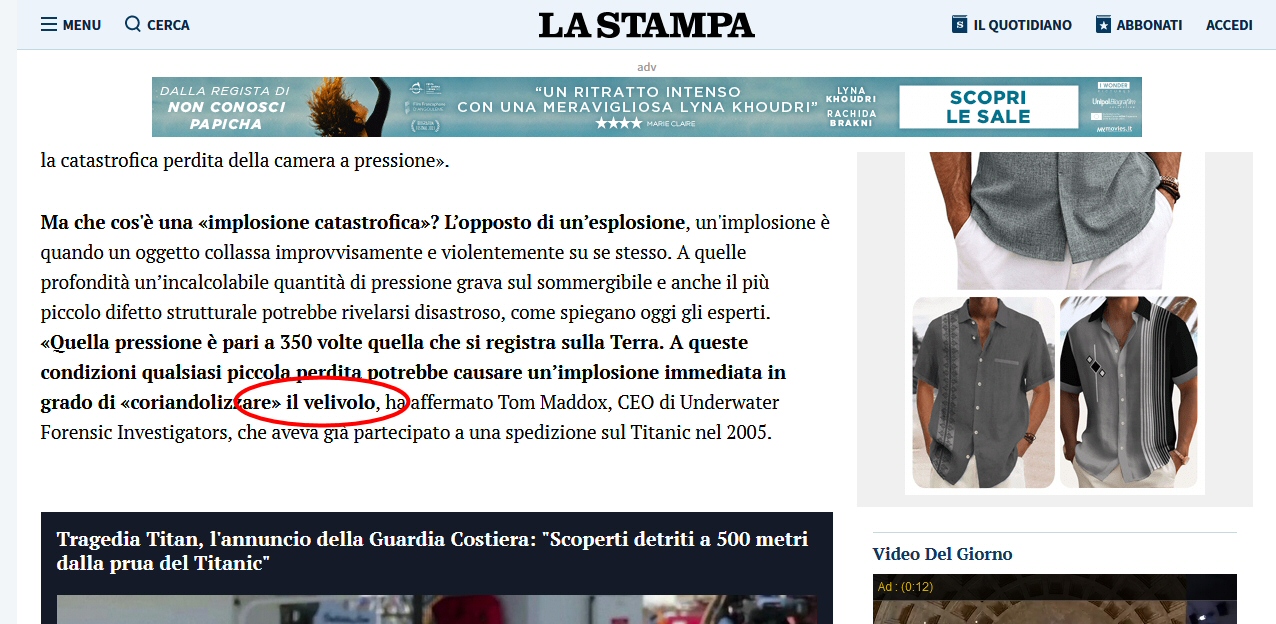
Intanto La Stampa, Panorama e il Fatto Quotidiano si aggiungono all’inquietante coro delle redazioni
inette, che a quanto pare sono piene di gente che non sa cosa voglia dire
velivolo. Gente alla quale andrebbe data una canna da pesca insieme a
un’interdizione permanente da ogni forma di giornalismo.
Anche qui, l’errore persiste e non viene corretto.
Il Fatto Quotidiano scrive la stessa fesseria: “A queste condizioni qualsiasi piccola perdita potrebbe causare un’implosione immediata, in grado di distruggere il velivolo”.
Il dilagare dell’errore madornale di usare “velivolo” per un veicolo
che va sott’acqua è forse partito dal
lancio ANSA
del 20 giugno, che oggi risulta riscritto e corretto ma che in origine (copia su Archive.org) parlava proprio di “velivolo” (“...nell’area di ricerca in cui il velivolo era scomparso due giorni prima”). Sembra che tutti abbiano copiato
ciecamente da ANSA senza farsi la benché minima domanda sul senso di quello
che stavano copiando.
Screenshot del lancio ANSA com’era il 21 giugno 2023 (Archive.org).
È disponibile subito il podcast di oggi de Il Disinformatico della
Radiotelevisione Svizzera, scritto, montato e condotto dal sottoscritto: lo trovate presso
www.rsi.ch/ildisinformatico
(link diretto) e qui sotto.
Buon ascolto, e se vi interessano i testi di accompagnamento e i link alle fonti di questa puntata, sono qui sotto.
---
[CLIP: YouTuber italiani parlano di Minecraft e tutorial di modding]
Minecraft è sotto attacco: criminali informatici si sono introdotti in due popolari siti di modding legati a questo gioco e hanno infettato il software scaricabile dagli utenti. Nel frattempo, sedicenti hacker filorussi bloccano numerosi siti svizzeri, e altri attacchi informatici sottraggono dati alle aziende di numerosi paesi sfruttando una falla di un fornitore di servizi.
Benvenuti alla puntata del 23 giugno 2023 del Disinformatico, il podcast della Radiotelevisione Svizzera dedicato alle notizie e alle storie strane dell’informatica, che questa settimana racconta tre storie recentissime di attacchi informatici, per conoscere meglio il mondo spesso mitizzato e distorto dei reati commessi attraverso Internet e capire quali sono le tecniche realmente utilizzate dai criminali online e come ci si può difendere. Io sono Paolo Attivissimo.