

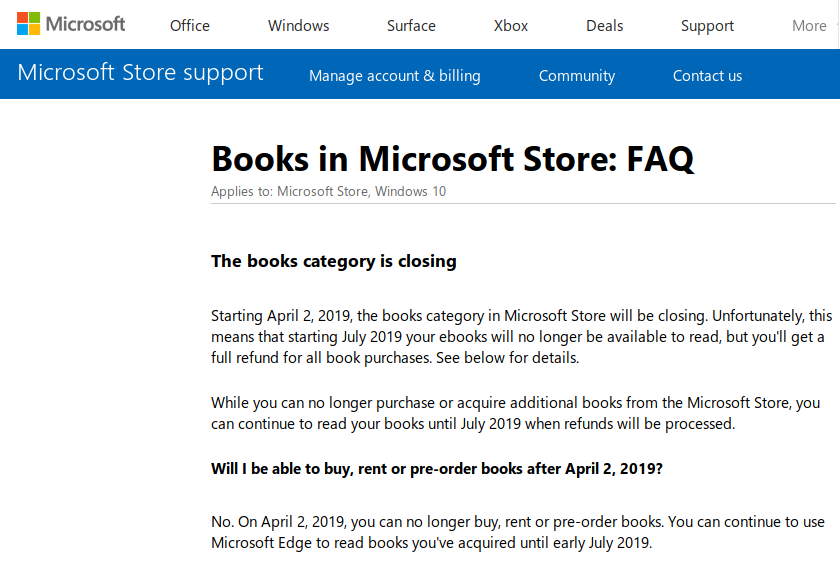
I libri cesseranno di funzionare. No, non è il titolo di un film distopico o una previsione di qualche catastrofista: è la sintesi di un annuncio fatto da Microsoft per comunicare ai clienti dei propri libri digitali che da questo mese tutti i libri acquistati dagli utenti nell’apposito negozio online di Microsoft non saranno più leggibili.
Questi libri, infatti, sono protetti da un sistema anticopia, il cosiddetto Digital Rights Management o DRM, per cui per poterli leggere è necessario che Microsoft mantenga attivi i siti che gestiscono questo sistema. Ma l’azienda ha deciso invece di disattivarli e di rimborsare gli utenti per le loro spese.
Per fare un paragone, è come se una libreria chiudesse e il libraio irrompesse in casa vostra, senza il vostro consenso, e vi portasse via tutti i libri che vi ha venduto, lasciandovi i soldi equivalenti sul comodino. Ed è tutto legale.
I libri digitali protetti dai sistemi anticopia, infatti, vengono solo concessi in licenza all’utente, non venduti a tutti gli effetti, anche se i negozi Internet che offrono questi libri solitamente usano il verbo “comprare”. Questa licenza è revocabile, e in questo caso è stata revocata.
Non è il primo episodio del suo genere: anche Amazon e Apple, in passato, hanno revocato licenze e tolto ai clienti le copie delle canzoni, dei libri o dei film lucchettati dal DRM. Ora è il turno di un altro grande nome del mondo digitale, e come in passato ci si scandalizza brevemente e poi tutto torna come prima.
Il risultato di questa indifferenza dei consumatori e dei legislatori è che sono sempre più numerosi non solo i libri e i brani musicali digitali vincolati dal DRM, ma anche i dispositivi soggetti a questa stessa revocabilità. Jibo, per esempio, è un simpatico robottino da 900 dollari che ora è inservibile perché il sito che lo gestisce è stato chiuso dai produttori. Se avete un altoparlante smart Alexa di Amazon o quello di Google, tenete presente che il suo funzionamento dipende dalla disponibilità dei server appositi di queste aziende, senza i quali è praticamente inutile. E se pensate che sia improbabile che nomi grandi come Amazon o Google possano chiudere, o decidere di revocare questi servizi, tenete presente che è lo stesso ragionamento che hanno fatto i clienti dei libri digitali di Microsoft. Che adesso si trovano con una catasta di bit illeggibili.
Certo, esistono dei programmi che tolgono questi lucchetti digitali ai libri, ai film e alle canzoni, ma sono quasi sempre illegali, pochi sanno come usarli, e comunque ricostruire un libro alla volta una biblioteca accuratamente selezionata è impraticabile. Anche se il DRM viene proposto come sistema antipirateria, insomma, ancora una volta si ritorce contro il consumatore onesto, mentre i pirati continuano ad operare indisturbati.
Prima di fare acquisti, insomma, a noi utenti conviene leggere attentamente le avvertenze, o chiedere il consulto di un esperto, per capire se quello che compriamo è veramente nostro oppure è in realtà concesso soltanto in licenza revocabile. Altrimenti rischiamo di lasciare ai nostri figli il nulla digitale.
Fonti aggiuntive: BoingBoing, The Register, Wired.com.








{kind=link}